Automating a Call Center with Machine Learning
Marton Trencseni - Sun 27 January 2019 - Machine Learning
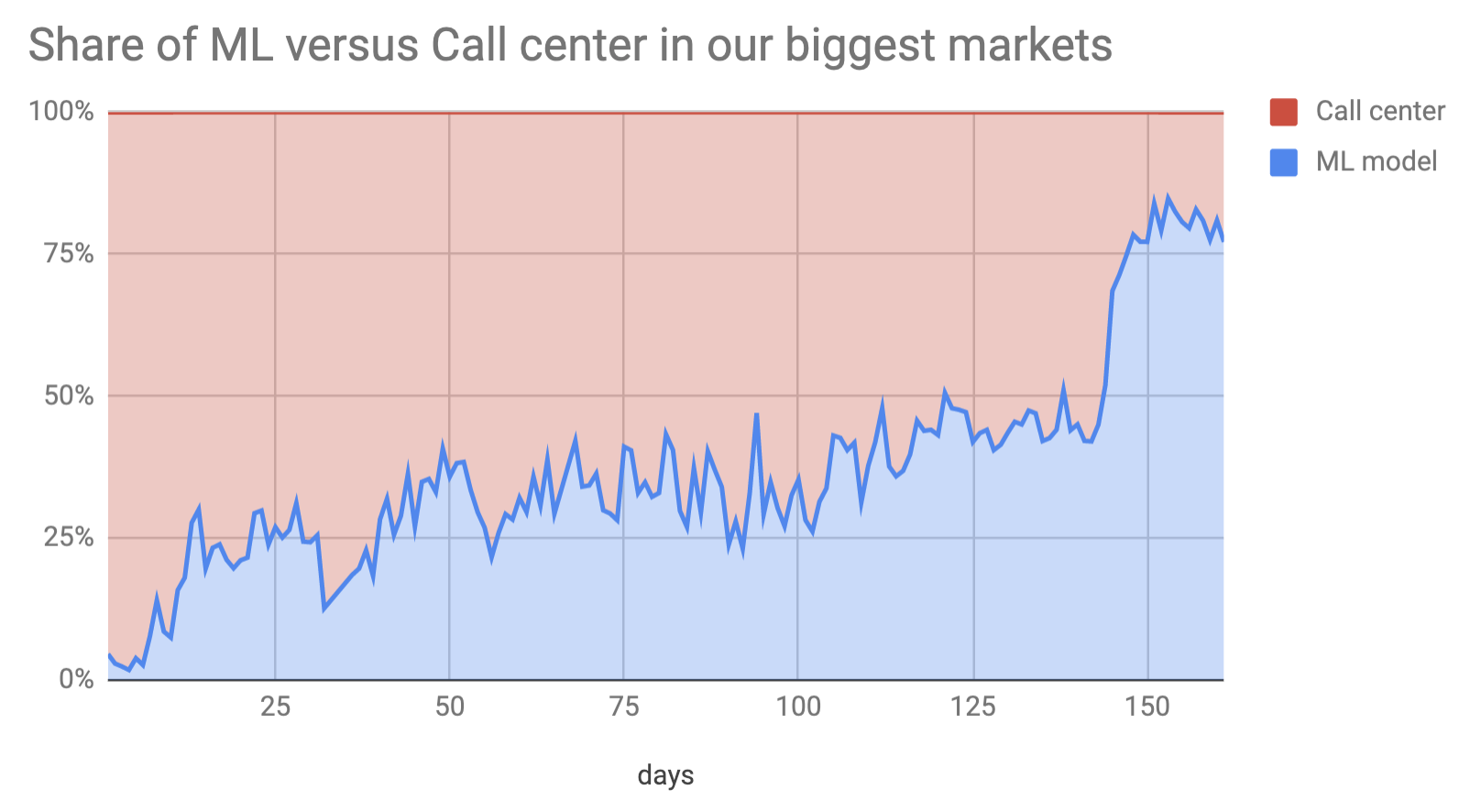
Impact
Over a period of 6 months, we rolled out a Machine Learning model to predict a customer’s delivery (latitude, longitude). During the recent holiday peak, this ML model handled most of Fetchr’s order scheduling.
Introduction
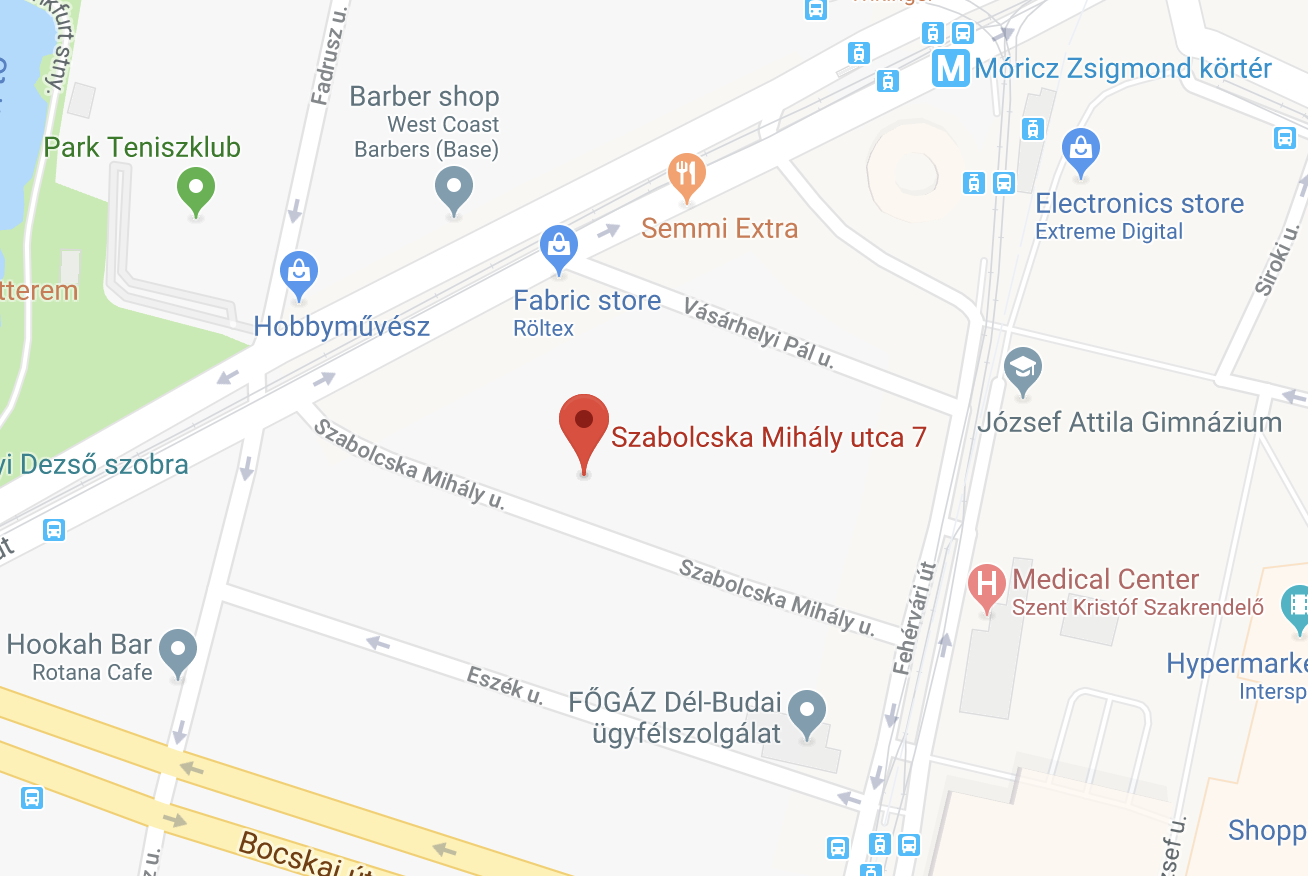
In Europe and the US, addresses is not something we think about a lot. My address in Hungary is, for example:
1114 Budapest, Szabolcska Mihaly u. 7
Here “u.” stands for “utca”, which means “street”. 1114 is my zip code in Hungary. Sometimes I’m lazy and I shorten it, like:
1114 BP, Szabolcska 7
In the US, it’s customary to write it out in a different order and “street” is dropped:
7 Szabolcska Mihaly, Budapest, 1114
If I open Google Maps (in an incognito window), I can enter either of the three, and it will point me to the precise (latitude, longitude) of my apartment, which happens to be (47.476117, 19.044950).
I can give either address string to a delivery company in Hungary, and they will find my apartment. Why does this work? In the US and Europe, the following all hold:
- zip codes exist and everybody uses them
- address formats are reasonably standardized
- most people know what their address is (“my zip code is 1114”)
- most people know how to write out their addresses
- companies like Google have a known database of addresses (and maps)
- companies like Google have an incentive to make services like Google Maps work
- web shops can enforce address formats, eg. can force the user to select from known zip codes, street names in those zip codes, etc.
In many countries in the Middle East, some of the above do not hold. For example, in the United Arab Emirates (UAE), there are no zip codes. There are street names, but which street a building falls on is often ambiguous. Also, streets have many names, official and slang, english and arabic. Often, people don’t know their streets: for example, I live in a hotel in Dubai, and I don’t know which street the building is on (more than half of the population in Dubai are expats). Sometimes buildings have a street number, sometimes not; sometimes people know the number, sometimes not. Finally, there are large areas, even in Dubai, where Google Maps doesn't know street names or numbers:
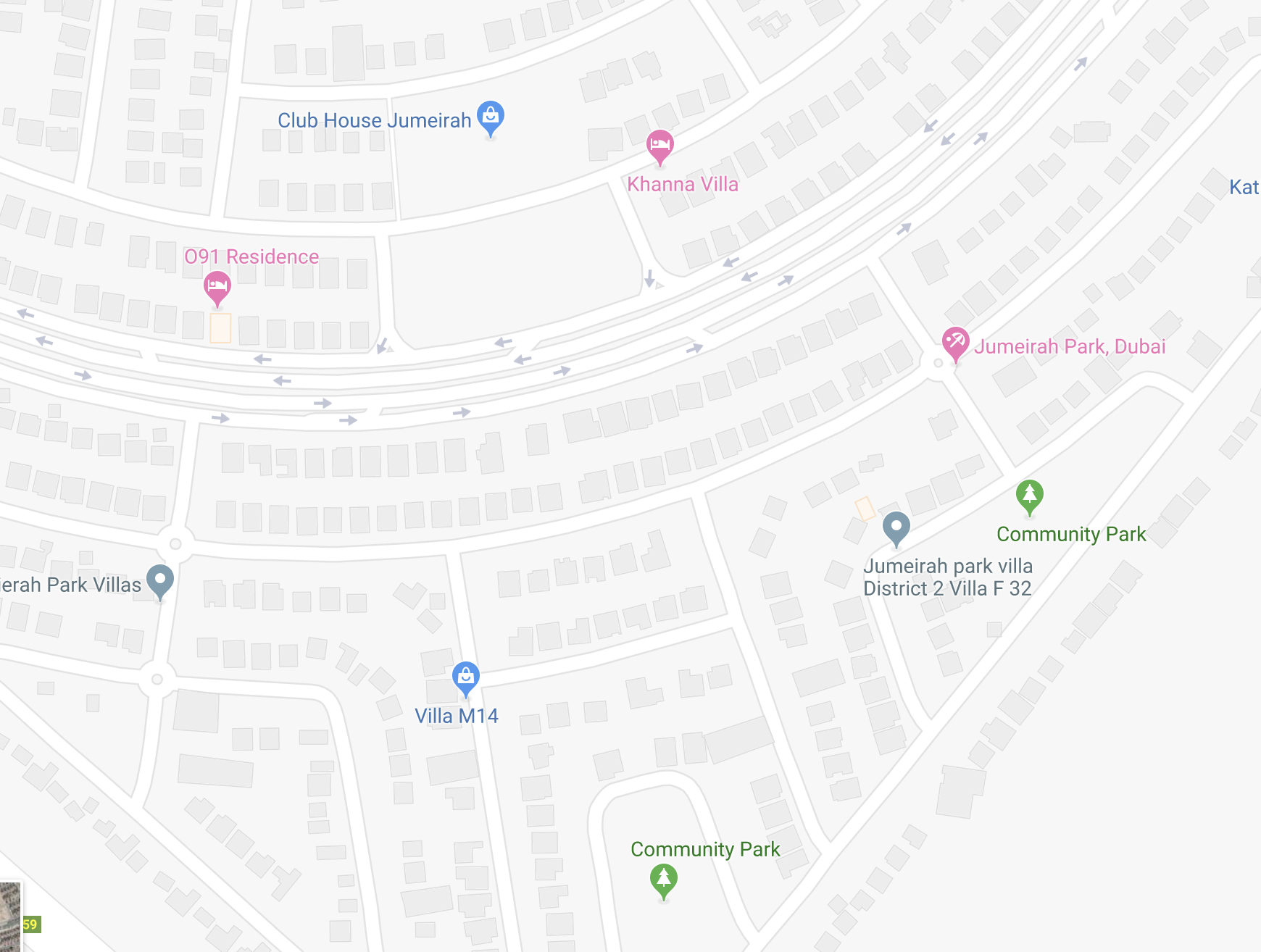
Many times people also don't give their street name as an address, instead they give an area name (which is itself ambiguous) and building name (“Princess Tower”) or a nearby point of interest (POI) like “near Burger King in Al Barsha, next to SZR” ("SZR" stands for "Sheikh Zayed Road", it's a 2x8 lane super-highway in Dubai). This is the situation in cities like Dubai or Riyadh; in remote areas, in the desert, resolving locations is even harder.
Note: Interestingly, a few years ago the UAE government created a system to identify buildings called Makani codes, which is a 10 digit number. Every building in the UAE has a Makani code, and every building must have a plaque showing the Makani code. Unfortunately, very few people know their building's Makani code; it’s not widely used (eg. I don’t know my building's Makani code).

Here are some UAE and KSA addresses Fetchr delivered to in the past (changed capitalization to improve readability:
- Near to Safeer Mall, Khuzam
- Greece Cluster, Building Greece 05 Shop 04, International City, Dubai
- Near by Emirates NBD, Nad Al Sheba, Dubai
- Batha Near Al Rajhi Building near Al Electron Building
- I work at Royal Green Golf & Country Club
- My home is near by colors street for car decoration in Jeddah
- Villa, King Khalid street, Down Town
Google Maps or Open Street Maps doesn’t help here!
The trick to a successful delivery in this region is the phone number! Unlike in the US or Europe, where an address is enough, here the phone number is king; no package is accepted without the customer’s phone number. For incomplete or ambigious addresses, delivery companies rely on calling the customer to figure out where to go: call the customer, and try to figure out where to send the package based on the conversation with the customer, and then the package is dispatched to that (latitude, longitude). This is called scheduling, the goal here is to figure out the spacetime coordinates of the delivery: (latitude, longitude, day, time), but we’ll ignore the (day, time) here.
Modeling
The problem we took on: given the freetext (phone, address), can we predict (latitude, longitude), so we can avoid a call to the customer? We set up a dummy service for this and got our software engineers to pass in the (phone, country, city, address); if we can make a good prediction, we return the predicted (latitude, longitude), else we return NO_PREDICTION, in which case everything happens as before, the customer gets a call. (This is actually an oversimplification, for example the customer can also self-schedule using our app or mweb.)
The service in production is running a number of models. A model is a way to predict the (latitude, longitude). When the service receives a (phone ... address) request, it goes through the models in a fixed order. If a model returns the (latitude, longitude), the service returns it. If the model returns NO_PREDICTION, it moves on to the next. The models which returns the best quality coordinates is the first in line, and so on.
So what models do we actually use? We currently have a total of 5 models running in production. I will describe 2 at a high level below.
Repeats
When working on building dashboards to understand our delivery operations, we created a metric which shows the % of our customers who are repeat customers. Customers can be identified by their phone numbers, which are also passed in as free text, but normalizing this is easy. It turns out we have a lot of customers that we’re already delivered to! This is an obvious opportunity: if we’ve delivered to a customer before, and recorded the actual (latitude, longitude) of the delivery (the driver app automatically does this when the package is delivered), then we can look this up. This should work most of the time, because people don’t move that often. This is the basic idea of this model (details omitted on purpose).
The repeat model is simple, but it works amazingly well. The delivery performance (out of 100 dispatches, how many deliveries are successful) of this model outperforms our call center, and is on par with customer self-scheduling (which is the best channel). Part of the reason is that repeat customers are a biased group.
Address matching
What about non-repeat customers? Can we know where to go just based on the address?
Initially we tried a lot of things, too many to detail here. Broadly:
- instead of predicting the (latitude, longitude), use a more coarse grained geographic division of zones (eg. divide Dubai into a few 100 polygons), and try to predict the correct zone; here we tried various approaches:
- building a separate model for each zone
- building one city-level model with multiple activations, one per zone
- decision tree and other models on feature vectors constructed from bag-of-words models, TF-IDF, etc.
- use raw OpenStreetMaps (OSM) data, extracting “sites”, and matching to that
- mixing-and-matching the above two
- various string tokenization and matching approaches
- etc.
After a lot of experimentation, I wasn’t satisfied with the overall performance of the models, and I didn't have enough confidence to put them into production. However, after weeks of working with the data, I realized that I can try something pretty simple “by hand”. I usually look at Dubai data, and I noticed a lot of addresses include the area name, which is pretty unambigious, for example “Jumeirah Village Circle” or “Jumeirah Village Triangle”.
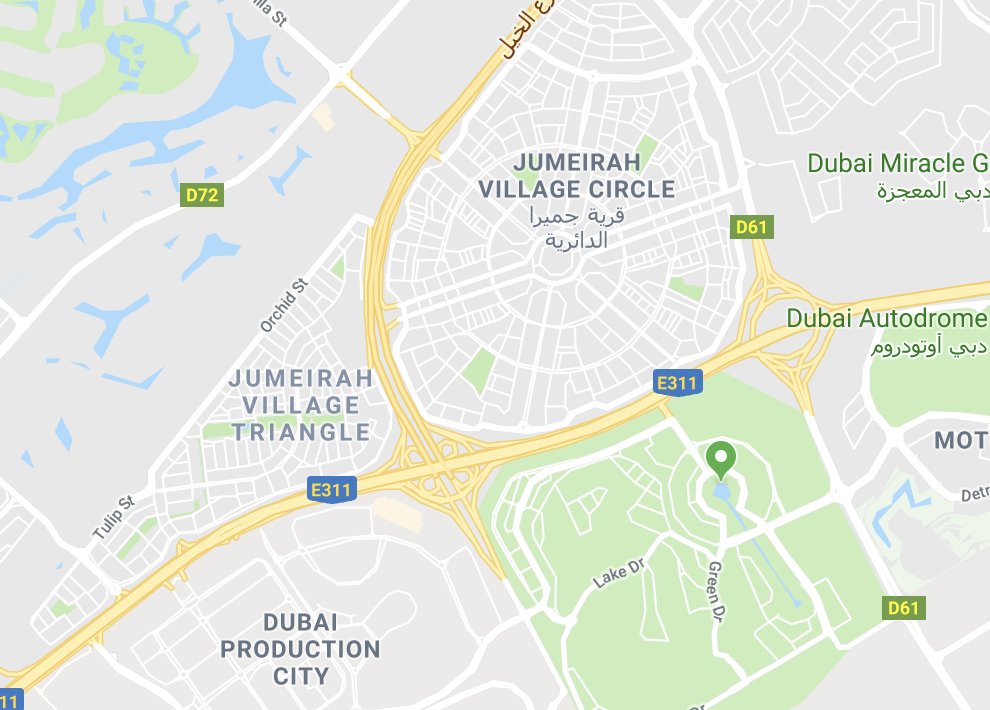
I knew that these areas were served by the same driver, because I’ve been out with him several times to understand what happens on the ground. So if the service returns the middle of the area as a (latitude, longitude) for those addresses, it’ll get dispatched by the correct driver, a good enough first step. So I spent a day looking at Google Maps and OSM and simply wrote out a few hundred rules by hand, did some quick sanity checks to make sure past addresses which would match these were in the right location, and then wrote a simple model which essentially does substring checking. I then put it into production for a few orders / day. A few days later I evaluated the delivery performance, and saw that while it’s not excellent, it’s not that bad. (I later removed this manual model from production, the ML version is much better).
So the question was, how do I make this better, and generalize it? I noticed this pattern while looking at the data, clearly there’s more patterns like this in the data, let’s get the machine to learn it. This is what we did: there’s a backend component, which looks at all our historic deliveries, and finds good rules, the production service then just uses these rules (details omitted on purpose). It's an interesting approach: a rule based engine in production, but the rules are coming out of an ML model; this makes it really easy to tune (see below) and add/remove exceptions.
Knobs to turn
A really nice property of our models is that they have knobs to turn. On the repeat model, we can accept better or worse address similarity when comparing to past addresses. On the address matching type models, we can accept more or less tightly packed historic coordinates when deciding which rule to run in production. This allows us to turn knobs:
- run models in “tight” mode, where we schedule less orders (more prediction queries return
NO_PREDICTIONand go to the call center), but the returned coordinates are very accurate and hence we get good delivery performance. - run models in “wide” mode, where we schedule more orders (less orders return
NO_PREDICTIONand go to the call center), but the returned coordinates are on average less accurate and hence we get lower delivery performance---but we pass less orders to the call center.
We can use these knobs to make choices. For example, if other scheduling channels are not available, it makes sense to run the model as wide as possible; and there's a break-even point, where the model performs as well on average as the call center.
Winner take all
The delivery market has a “winner take all” dynamic: more order volume means higher density, means more loaded drivers, means more efficient drivers, means lower cost. This also applies to the ML models. The more deliveries a company has made, the more repeats it will have (eventually, it will cover the entire population of a country/city). The more deliveries a company has made, the better address rules it can extract from its data. More past deliveries lead to higher efficiency today.
Statistical improvements
There are a lot of ways to improve these models. The simplest one is based on counting. Using the address matching model as a use-case, we can simply count how many dispatches are coming from each rule (like the toy model example “jumeirah village triangle” -> (latitude, longitude)), compute the delivery performance (=deliveries/dispatches) for each rule, and prune the badly performing ones. There’s an exploration-exploitation trade-off here, so we use an epsilon-greedy strategy. For more on this, see multi-armed bandits.
Metrics
Good Machine Learning goes hand in hand with good Data Engineering and Analytics. This project came out of building 100s of charts and metrics to understand and visualize Fetchr’s operations and business. For this project, the most relevant were:
- Repeat %: what % of our daily dispatches are going to customer we’ve delivered to before; the higher, the easier it is to do a good job on predicting customer location and behaviour based on past data. Since Fetchr is very successful and operates at scale, we have a fair share of repeats.
- Scheduling accuracy: scheduling accuracy is the % of deliveries where the scheduled coordinate and the delivery coordinate is within X meters. The challenge is, the delivery coordinate is unreliable: sometimes the drivers update the order status hours after the delivery event (eg. while having coffee), so the delivery coordinate is unreliable. The scheduled coordinate itself could also be incorrect. But when the two are close together, it’s very likely that they point to the correct location. Scheduling accuracy can also be benchmarked when back-testing models.
- Delivery performance: Delivery performance is a daily metric, it’s the % of dispatches that are successfully delivered. Delivery performance is not something we can back-test when building models, it has to be measured in production, experimentally, eg. on a small 1% release. (Delivery performance is the One Metric That Matters for delivery companies, we live and die by it.)
- Scheduling channel splits, model splits: also a daily metric, it shows what % of dispatches came from which scheduling channel (call center, ML, self-scheduling, etc.), and specifically for the ML channel, what % came from which model.
- Conversion: of all orders passed to the ML model for coordinate prediction, what % do we return a coordinate (instead of
NO_PREDICTION)
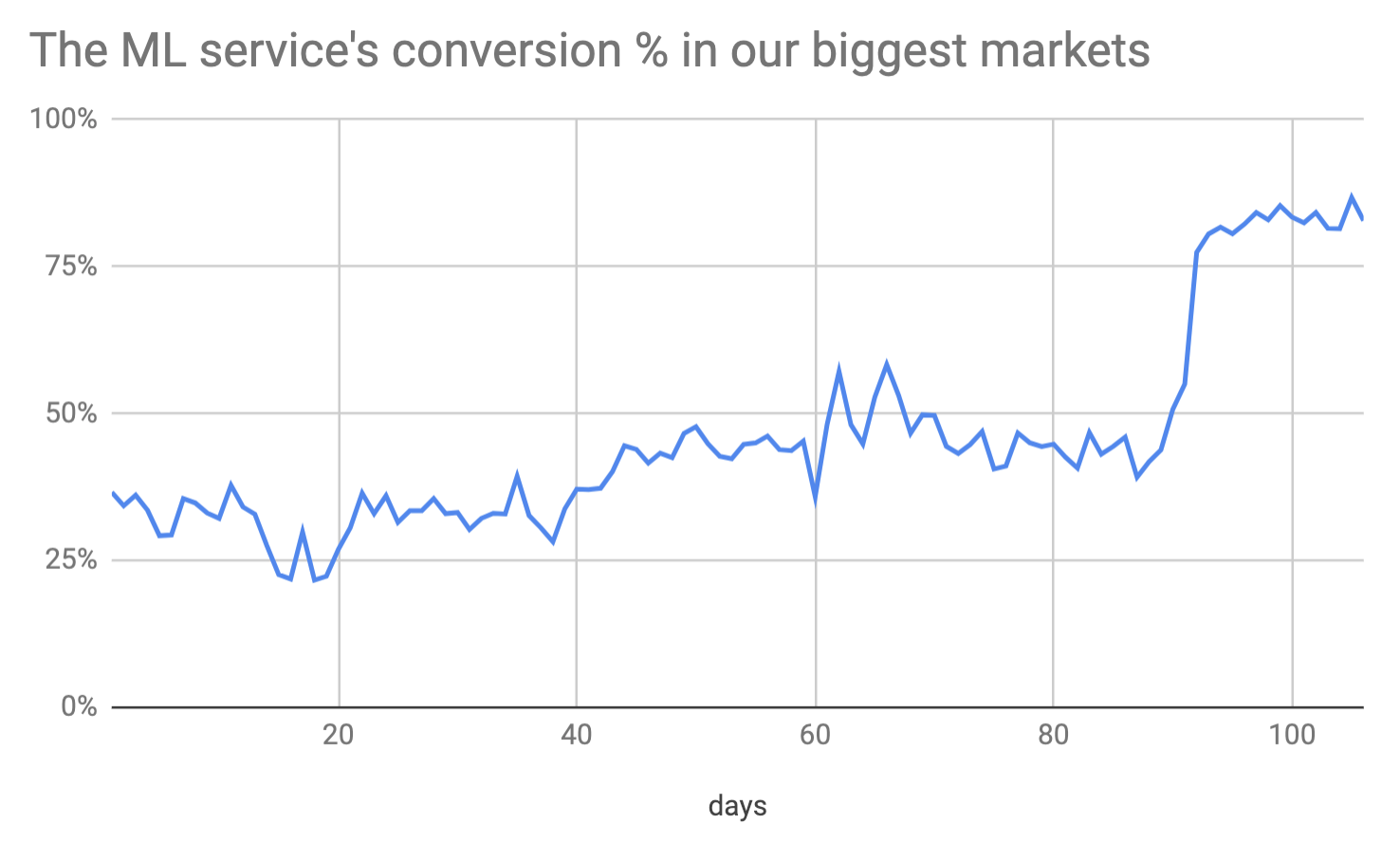
Conclusion
The delivery coordinate prediction service has been a great success at Fetchr. The version currently in production is relatively simple, easy to understand and tunable, and adding exceptions is easy. There are lots of improvement opportunities in the current models themselves, ordering of models based on features, and of course making more complex models. Our goal is to go further up and toward the right in (conversion, accuracy) space!