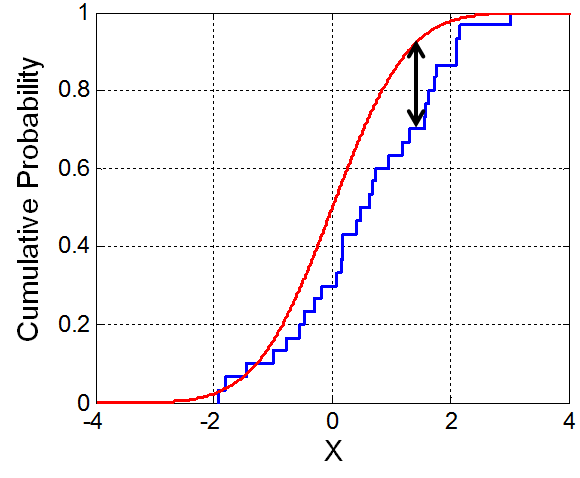
Why are Randomized Controlled Trials (RCTs, known as A/B testing in much of the industry) testing is widely regarded as the golden standard of causal inference? What else can a Data Scientist do if A/B testing is not possible, and why are those alternatives inferior to A/B testing?
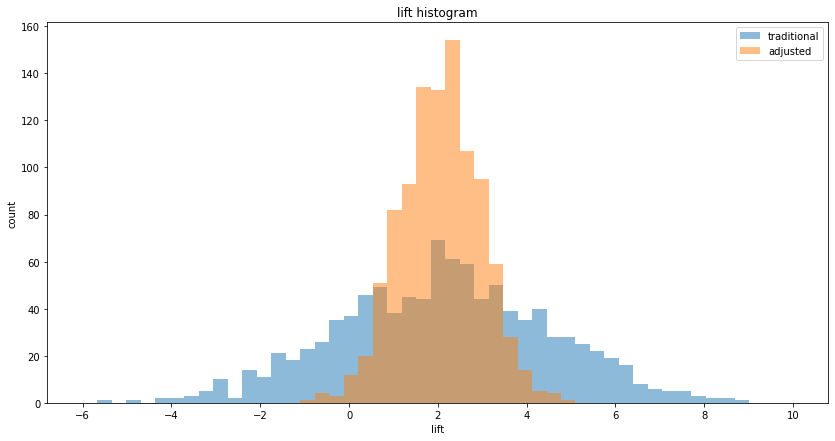
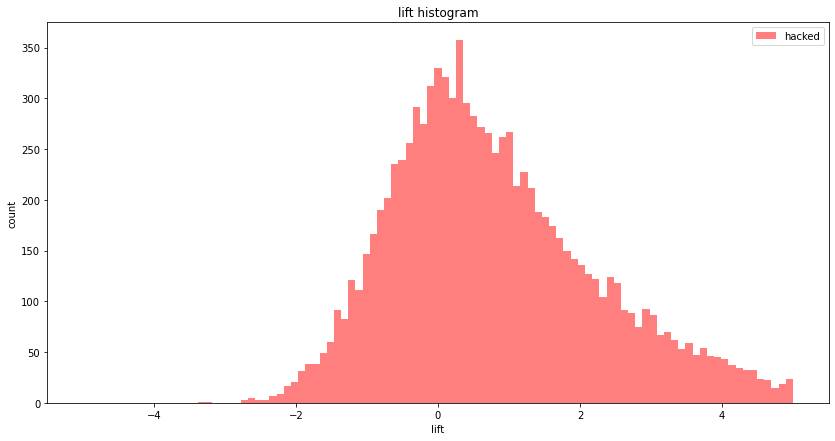
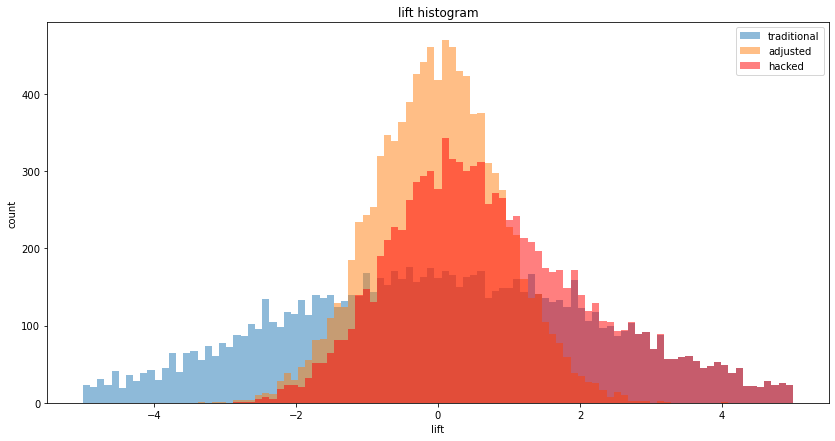
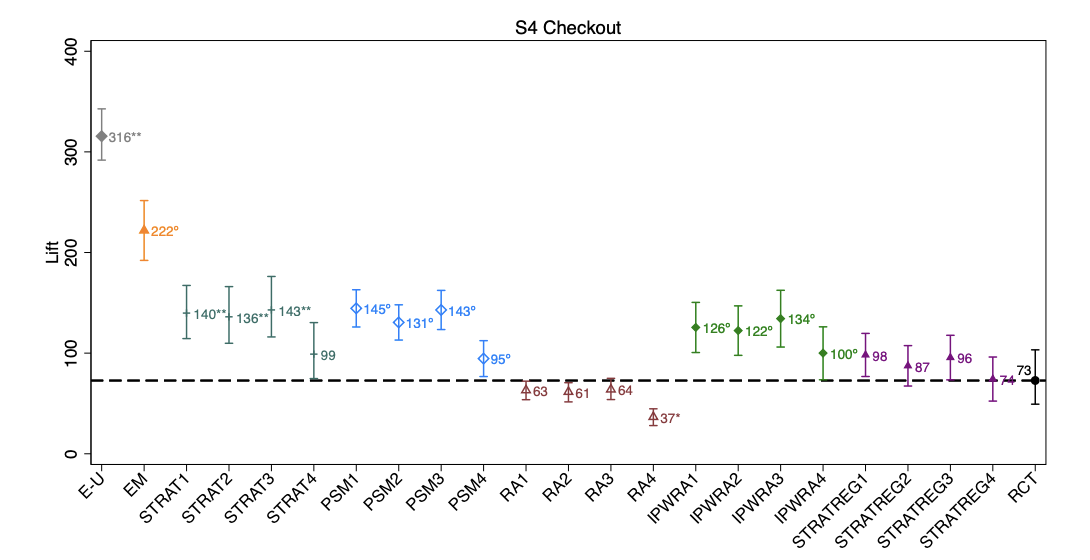
This papers shows, using 15 experiments (for ads on Facebook) where a RCT was conducted, that common observational methods (run on the Facebook data, by ignoring the control group) severely mis-estimate the true treatment life (as measured by the RCT), often by a factor of 3x or more. This is true, even though Facebook has (i) very large sample sizes, and, (ii) very high quality data (per-user feature vector) about its users which are used in the observational methods. This should be a major red flag for Data Scientists working on common marketing measurements (such as marketing campaigns) using observational methods.
Continue reading