2024 Data Outlook
Marton Trencseni - Sun 11 February 2024 - Data
Introduction
It is the beginning of the year — a good time to reflect on the previous year and make plans for the year ahead. This document is an attempt at that, focusing on the latter, since our 2023 performance reviews covered the previous year.
I invite you to the same for yourself — think about what happened to the industry in 2023, where it's going in 2024, and what does that mean to you? What do you want to learn, whether at the company or outside? What do you want to "import" into the company, whether into an existing project or as a new project? What does a good 2024, the year of AI, look like on your area, in your Business Unit? What do you want to do more of, and what do you want to do less of — both at work and outside of work.
2024 will be a great year for data.
It will be what we make of it.
It will be what you make of it.

Industry opportunities
Data Science and AI
I started studying at the Technical University in Budapest in 1999 for a Computer Science major. Around the third year we had to take the mandatory Artificial Intelligence course, taught by the polish-hungarian professor Dobrowiecki Tadeusz. We were using the dreadful Norvig Artificial Intelligence book, but even worse, the hungarian translation, by Tadeusz, himself not a native speaker.

I didn't get much out of this course, but I do remember some things:
- Learning that neural networks are very limited: a neural network — even with multiple "hidden" layers — is essentially a linear transform, a large matrix that maps vectors into vectors
- .. but, no linear map can implement even XOR — this is of course is true, but only if you don't have activation functions in there. Once you add activation functions, you introduce nonlinearity, and the network can "even" learn XOR 🙂
- AI springs and winters: Tadeusz explained to us that optimism about the role of AI comes and then goes, with long periods of AI winters in between. "This time it's real!" has been said many times, but so far it always ended up being unreal.
- The first AI winter was triggered by the 1969 book Perceptrons, written famously by Marvin Minsky, and using — among others — the above XOR argument to discourage work in AI.
In 2024, after ~50 years of research, we know that the great man (Minsky) was wrong. We now understand the importance of activation functions, stochastic gradient descent, batch learning, dropouts, different cost functions, regularization, we have invented transformer architectures, and so on. I pay \$20 per month for my OpenAI subscription and use ChatGPT on a weekly basis, and I can't wait for further commoditization, so the monthly price drops to \$5 and eventually \$0. The opening image was drawn by ChatGPT4 (after numerous re-prompts by yours truly, because it kept drawing male figures only). Even John Carmack (creator Wolfenstein, Doom, Quake, then CTO of Oculus) is working on AI these days. "This time it's real!"
The transformer neural network (and training) architectures driving Generative AI are interesting technologies, and I don't think we should (or can afford to) ignore them. In 2024, having a good grasp of how and why they work is part of the forward-thinking (and intellectual) Data Scientist's (or ML Engineer's, or, any data person's) area of interest. Also, there are hundreds of startups trying to commercialize these technologies (Word+GenAI, Powerpoint+GenAI, Jira+GenAI, IDE+GenAI, etc). We need to keep our eyes open for possible application areas within our company.
Personally, I have spent a fair amount of time in the past learning about and training neural networks (in the pre-generative era), in 2024 I plan to invest time into this area again, eg. play around with Llamas, play around with vector databases and langchain.
But it's not just the latest and greatest Generative AI that is exciting in 2024. The investment and excitement into (neural network based and/or generative) AI spills over into adjacent technical areas of traditional Data Science and Machine Learning (and Data Engineering), so we have new forecasting libraries, new vision models, better implementations in SKL and LGBM, and tons of technologies to try out on the MLOps and tooling front — literally 100s of tools and libraries.
Data Engineering and Platforms
This is one of the most exciting areas for us in 2024! When we built our organization's Data Strategy for 2024, our data platform and the data engineering work was the center piece of the plan!
There's so much to do, I don't have to sell it — this stuff sells itself. In 2024, we want to:
- detach from "corporate IT" and build out own way-of-working (eg. with devboxes)
- significantly improve our developer experience
- replace Vertica with a managed DWH solution (such as Snowflake)
- stop building N DWHs and just have N=1, ours
- ..and thus, ingest from a lot more source operational databases
- move more of our ingestion to be real-time (vs batch)
- build out a set of core datasets
- build a new, thin ETL framework on top of Airflow
- .. and open source it!
- significantly improve our pipeline and dataset monitoring and alerting
- significantly improve the way we deploy, track and update models in production (MLOps)
- sunset significant portions of the Data Science infra, as move to a unified platform
That's 10+ items, each of them non-trivial!
Some technologies that I want to look at in 2024:
- DagsHub: GitHub for machine learning
- OpenLlama: let's make our own LLM
- DevBox: open source dev box management
- Airflow 2.8 and beyond
- I think we're getting a lot of bang for our buck from Airflow
- I ❤️ Airflow, I've been using it since 2017 (!)
- .. but, I wonder what's next?
- Today we use Airflow for ML pipelines, but it seems inefficient
- DataHub: we have already deployed it, we need more adoption \

AI products
Traditionally most of our product-work is adding Data Science to an existing product: e.g. we have our loyalty app, it displays offers [anyway], can we rank them better? We have our cinema app, it shows movie recommendations [anyway], can be rank them better? We send out marketing emails [anyway], can we personalize them better? To be clear, there is no problem with the [anyway], in the end it's impact that matters! Having said that, it's interesting to ponder whether the new AI technologies available in 2024 enable us to do new things, ship entirely new products or experiences [for the company]?
For example, I've been thinking that Amazon has Alexa, which among other functionalities, allows one to order products from Amazon by voice. It would certainly be easier to build something like Alexa today, given that voice recognition and intent recognition is more commoditized today.
Having said that, some of us have seen the difficulties in execution around previous AI apps, and we know it's hard to find engagement with Business Units over the Generative AI prototypes we built previously, so AI products are a very long shot, but still something we should think about.
Finance: an opportunity?
When I was getting my Physics degree at the Eotvos University in Budapest, I took a class on quantitative finance. The context is that in the US, around the 80s and 90, (some) physicists started to work in the finance industry, on Wall Street, as quants, building models [to find arbitrage opportunities]. In today's lingo they were "Data Scientists in Finance". At a high level, they were (and are) doing the same thing as we do as Data Scientists: trying to build forecasting and decision support models based off data to make more money, using mostly the same tools that we use (simple math, statistical tests, linear regression, decision trees, etc). This phenomenon became so widespread that one such physicist quant called Emanuel Derman even wrote a book about it titled My Life as a Quant, which I read as a University student. And we had a few such quant physicists in Budapest too, working at our local banks (and Morgan Stanley, who has an office in Budapest), so eventually they also taught a course at University. So ever since then I've been interested in understanding how quantitative finance works, and following this area from a distance. Somewhat related to this, I've also been reading a lot of investing related books in the last 10 years, many by or about Warren Buffet, James Simons, George Soros, Ray Dalio, etc. What does this have to do with our work as Data Scientists?
One thing I've been pondering is the success we have had working with the Financial Planning & Analysis (FP&A) teams. Over the last 12 to 18 months we proved that we (Data Scientists) are able to make significantly better (less biased), more objective forecasts than Finance teams. We are also able to better create what-if scenarios to model and understand the impacts of events such as pandemics, boycotts and wars. We are now not just forecasting revenues, but has also started to work on forecasting costs.
Over the winter break I was reading the excellent book In Pursuit of the Perfect Portfolio, about luminaries and their work in the Finance industry: Markowitz, Sharpe, Fama, Black, Scholes, etc. They invented modern portfolio theory with the idea of modeling risk vs return, covariance and diversification, CAPM and efficient fronter, efficient market hypothesis, Black-Scholes option pricing formula, etc. This is all stuff I've leared at University 20 years ago. When I learned about these, and most of the time when I read about these, it's in the context of trading: you are investing/trading, where do you put your (or your hedge fund's) money, how much do you diversify, etc. One thing that surprised me was that many of their original papers were addressing these topics in the context of corporate finance.

So I've began thinking: currently the role of data (and data science) is to improve execution when the company decides to do X. But what about helping to decide what X to do and not to do, ie. where to invest money, or not to invest, and how to balance this portfolio? In other words, given where and how we can invest money [+]:
- what are the expected returns?
- what is the best way to approximate returns?
- what are the risks and covariances?
- what is the best way to approximate risk and covariance?
- in the language of CAPM, what is the efficient frontier for our company?
In practice this may work out to be very similar to the Monte Carlo / variance project that we worked on previously, where they supported decisions by creating a distribution of outcomes (vs point estimates), which reportedly had significant impact.
[+] This is the exercise we play every year Q4 called budgeting: we ask for money.
Personal Development
One of my 2023 OKRs for Data Science was "Build a credible career path for Data Scientists", where I scored 0. I want to change this 0 to a 1 in 2024, also for Data Engineers and Platform Engineers.
The fundamental problem is that we are a small organization, with 12 Data Scientists (6 Dubai, 6 Remote), and even less Data Engineers (2 Dubai, 2 Remote) and Platform Engineers (4 Dubai). We have very small population per function, and it's hard to establish statistical baselines/calibrations at each level, especially with most people working alone (esp. DS), and having to do be able to "swim" alone in the "stormy waters", irrespective of level. At tech companies, with 100+ populations per function, the people making the promotion decisions are of the same function, but ranked higher (the people deciding about the promotion of a Data Engineer are the TL/Data Engineering Manager, Director DE, VP DE, CTO, all technical folks. For us this is not the case — of the roughly 5-6 people who need to agree to do a promotion, most will be non-technical. So the reason for promotion needs to be something that non-technical people understand. Examples that seem to work:
- Alice is a Data Scientist, but is also leading a team of 4 Data Engineers
- Bob is a Data Scientist, we have a big PAIN [+] in area X, and Bob solved it
- Alice led project X to completion and project X was highly visible to executives
- Bob is critical to keep the lights on, otherwise PAIN
- Alice is already managing 5 people of the same functions
- Bob had X million AED impact this year
Realistically, we need at least 2 of these for a strong promotion case.
[+] PAIN needs to be something that non-technical management understands, like escalations
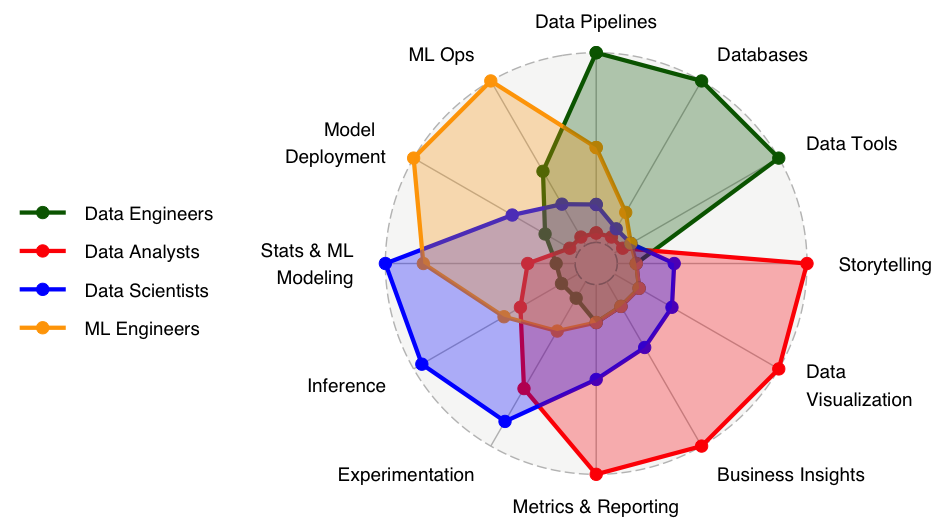
- We need to create personalized plans for everybody that attempt to create these situations.
- We will create the plan by understanding the strengths and weakness of everybody, and where they want to improve, along dimensions like in the spider chart above.
- It's the person's job to remember this plan and work on it continuously!
- We need to accept that there's an element of luck, in the sense that the environment also plays a role, and we don't control all of our environment.
- We create our own luck, and, luck favors the prepared. Eg. if there's an opportunity to work on a high-impact, high visibility project, it's likely we will pick somebody who is already performing at a high level, because that's the right choice for the organizatioon. So even if you feel you're currently not in a lucky situation, you need to run at high performance, so when the opportunity comes, you're in a good position to leverage it.
Job security and layoffs
We are not planning layoffs — this has not been on my mind for many months. The reason I added this section is that — to my surprise — some tech companies started doing layoffs in the second week of January: Google, Twitch, Amazon, Discord, etc.
As I just said, we are not planning layoffs. Also, even that were the case, we're already a very barebones team, so I personally am not worried. Having said that, in 2024, like in every year, the best strategy to hedge the risk of job loss (for you, me and everybody) is to:
- be a high performer
- work on your visibility, so people know you're a high performer (!)
- "be so good they can't ignore you", so in case it comes to it, you quickly get a new job
- outside of work, invest time and energy into thinking about your personal finances and investments — the best job is the one you don't really need 🙂

The part in quotes is a reference to Cal Newport's excellent book So Good They Can't Ignore You (originally a quote from comedian Steve Martin), which I read many years ago, and I found to be true:
Georgetown University professor Cal Newport debunks the long-held belief that follow your passion is good advice, and sets out on a quest to discover the reality of how people end up loving their careers. Not only are pre-existing passions rare and have little to do with how most people end up loving their work, but a focus on passion over skill can be dangerous, leading to anxiety and chronic job hopping. Spending time with organic farmers, venture capitalists, screenwriters, freelance computer programmers, and others who admitted to deriving great satisfaction from their work, Newport uncovers the strategies they used and the pitfalls they avoided in developing their compelling careers. Cal reveals that matching your job to a pre-existing passion does not matter. Passion comes after you put in the hard work to become excellent at something valuable, not before.
In other words, look out for areas where you have an opportunity to excel, work hard, invest a lot of time to become a master in that area, and then enjoy the fruits of your work. For example, if you're working on forecasting projects, you should become the master of forecasting and financial data science, even if he had no a priori "passion" for this topic back when he started working on this 2 years ago. Then, once you're the undisputed master at the organization, then you'll enjoy it, and maybe it will feel like you had passion all along!
Books
In no particular order, here are some books relevant to 2024 (that I have read or have bought and plan to read):
- Experimentation for Engineers
- Reliable Machine Learning
- Information Theory, Inference and Learning Algorithms
- Making Databases Work
- collection of Stonebraker papers
- he's the father (along with Jim Gray) of much of the database technology we use today
- started Ingres, which then became Postres
- The Staff Engineer's Path
- Pradeep is reading this
- Patterns, Predictions, and Actions
- I've already read this, highly recommended
- Financial Econometrics
- because I mentioned Markowitz and CAPM
- Beautiful C++
- I've already this, highly recommended
- as a former C++ programmer, I'm always looking for ways to bring back C++ into my life 🙂
- Machine Learning Design Patterns
- The Little Book of Deep Learning (recommended by the legendary John Carmack)
- Deep Learning: Foundations and Concepts
- Understanding Deep Learning
- The Science of Deep Learning
- Efficient Linux at the Command Line
- Mohit is reading this
- System Design Interview Volume 1 and Volume 2
- Machine Learning System Design Interview
- I've read all 3, they are great
- One of the best ways you can learn how other companies do things is to see what they ask on interviews
- Here, the author has done this work and asked lots of people at big tech companies, and compiled it into these books!
- CPython Internals
- I read this, I didn't get much out of it
- CPython mostly works as you'd expect it works if you know the basics about compilers and interpreters
- So Good They Can't Ignore You
- My Life as a Quant
Note: I definitely buy more books than I can read..
Personal reflections
In 2024 I plan to make some minor modifications to how I manage myself:
- be more rigorous with keeping a daily log
- write weekly updates
- defend my time better
- I think I spent a lot of time in 2023 in pointless meetings, which ultimately didn't add any value for the company o rme
- eg. reduce time spent in 1v1s, but increase the effectiveness: I continue to strongly believe in 1v1s, but my hypothesis is that a lot of my hours spent in 1v1s in 2023 was not effective
- .. but, 1v1s are not the main culprit, it's just "too many pointless meetings"
- write more
- eg. documents like this
- in the last couple of months I've been thinking a lot about the productivity of people like Elon Musk — why is it that some people are 100x or 1000x much more productive than me?
- of course billionaires who own multiple companies and tell 1000s of people what to work on have significantly higher leverage, so there is no real mystery here 🙂
- there are lots of self-help books written, with advice like "wake up at 5am", "write lists", etc.
- this is actually good advice, I do a lot of things like this (but far from perfect), and I think things like this can 2x your productivity
- the one thing I notice when reading stories about highly successful people is that they have the ability to be demanding (vs always just being nice)
- a little bit like when I said in Q1 "everybody owes me a Generative AI prototype"
- maybe I should be more like that
- with myself and others
- stretch goal: in terms of the way we run, we are essentially a remote team: how should our tooling look like, given that? eg. simple things like vacation tracking or who-is-in-the-office are still not solved