Arabic name classification with Scikit-Learn and Pytorch
Marton Trencseni - Fri 02 August 2019 - Machine Learning
Introduction
Many times, a delivery company doing parcel deliveries on behalf of its clients to the clients’ customers (the recipients) doesn’t have a direct relationship with the recipient herself. All it has is the parcel, the attached name and address, and maybe a product description on the airway bill. Nevertheless, there are numerous steps in the logistics funnel when the delivery company would like to communicate to the recipient; the simplest example is sending an “I’m coming” notification on the day of (attempted) delivery. These notifications themselves present rich opportunities for data scientists for experimentation. One simple thing is to get the language right. In the Middle East, in countries like the UAE, more than half the population is expats, so we can probably do better than a country default.
In this region, the simplest base case is to tell an arabic name apart from a non-arabic name, and assume that arabic/english notifications work for those two cases. While working on this arabic-vs-rest classification problem, I was curious how good out-of-the-box models perform with publicly available data, and then compare that with what we can achieve with internal data / features derived from millions of deliveries.
The code and training data is up on Github.
Building a training set from publicly available data
Fortunately there are some publicly available datasets that we can merge to get training data. Specifically, I used these sources (first 4 for arabic, last for english):
- https://en.wikipedia.org/wiki/List_of_Arabic_given_names
- https://github.com/zakahmad/ArabicNameGenderFinder
- http://www.20000-names.com/female_arabian_names.htm
- http://www.20000-names.com/male_arabian_names.htm
- https://github.com/ligi/HiLoCo/blob/master/app/src/main/res/raw/names.csv
Using these sources I created a training set of 10,000 names:
- 5,000 arabic, 5,000 english
- 8,000 for training (balanced)
- 2,000 for testing (balanced)
Some arabic examples: ahmed, ghalib, hasna, salar, afruz. Some english examples: john, westwood, eldon, corina, margareta.
The names are cleaned: ASCII a-z letters only; all lower-case; at least 3 characters long; some arabic names are also common in english speaking countries (like ahmed or ali), these were removed from english; and so on.
Model training
I specifically wanted to see how bag-of-chars feature vectors perform against one-hot encoded ones; other than that I just wanted to try a bunch of models I had anyway from previous SKL and Pytorch projects:
- logistic regression
- simple decision trees
- Random Forests
- Gradient Boosted Trees
- Neural nets
- fully connected deep NNs in Pytorch,
- and finally CNNs in Pytorch.
I won’t go into the details of these models, I will just show results.
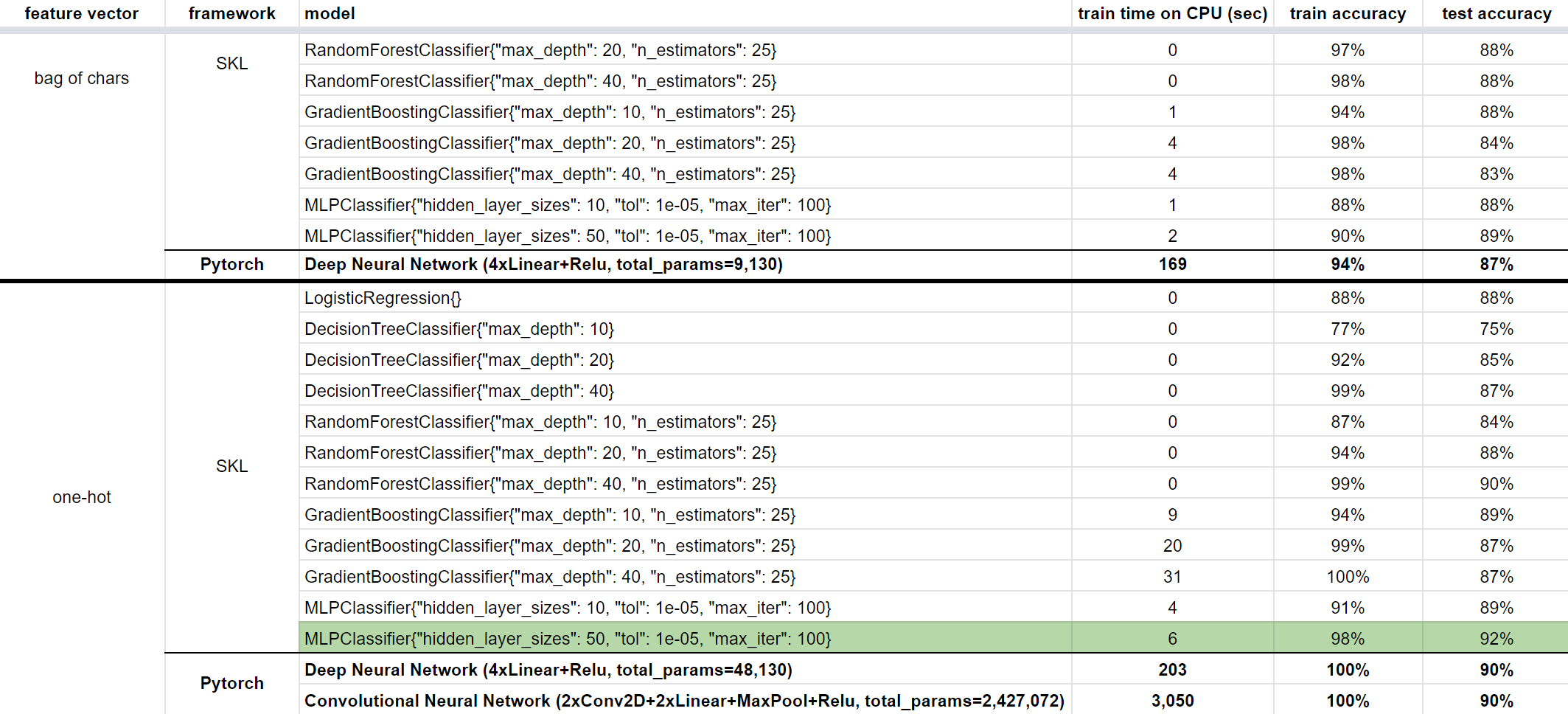
My observations:
- the tree based and NN models have enough parameters to learn the training set (train accuracy approaches 100%)
- the neural nets don't outperfom the trees
- neither model is able to go significantly above 90% test accuracy, so generalization is limited
- 90% is not good enough for production on this problem (although that wasn’t the goal here)
- I was expecting one-hot encoded models to pick up on useful trigram features, but they don’t significantly outperform the simple bag-of-chars models; I was expecting the CNN specifically to outperform the others here; the reason is that if characters in a trigram are far apart in terms of the one-hot coding, the CNN is not able to pick it up directly, only in downstream "averaged" layers
- I was training the Pytorch models on my laptop’s CPU, that’s why the Pytorch training times are so high; it’s interesting how much slower the Pytorch network training is than SKL’s MLPClassifier (which is also a deep neural network); possible reasons: the MLP has a lot less parameters and/or the Pytorch models have ReLu() and other non-linearities
Doing much better with a lot more data
Note: these datasets derived from internal data, and the models tied to it, are not shared.
Since we do millions of deliveries, specifically in the countries of interest to us, we have the potential to have much more training data than the datasets above. The challenge for us was ground truth: our historic deliveries are not labeled for arabic/rest. Fortunately there are tricks we could use (other available fields, frequency, etc), to create a high-quality arabic names dataset for each of our target countries. As is usual in these projects, 80% of the work went into creating a high-quality dataset; once this was done, builiding a predictor was simple. In the end, the best-performing model is a hand-tuned tri-gram based model that also uses frequencies of names (not part of the public datasets), and achieves 99% accuracy. It only gets confused on names that genuinely sound like they could be arabic (but are actually not, or are shared arabic/indian names). I leave it to the reader to change the models/feature vectors above to be bag-of-trigrams, it should only be a few lines of code changes.
Estimating impact
A model like this (once we’re reasonably sure it’s accuracy is good enough that we can trust it for making estimates) is not just useful in production, but also for estimating its own impact. By running it on (unseen) past delivery data in our target countries, we can see how much of an impact the model will have in production: there are various “naive” ways to predict language (always arabic, always english, use information from other fields), and we can compare the accuracy of these to what we can achieve with our model, to get the additional % of deliveries where we will get the notification language right. If we also have an estimate for how much getting the language right lifts the probability of delivery success, we can estimate the overall lift in delivery success, which is then easy to translate to dollars (or dirhams). If any of these multpliers is not available in this Fermi-decomposition, then we can always perform an A/B test to see the impact. For us, running this estimate shows that the model will be most useful in the UAE; this makes sense, there are lots of expats in Dubai; and, interestingly, another GCC country, where most of our deliveries go to arabic names, but this would be hard to tell without the predictor since the recipients give their names with english letters (ie. not with arabic Unicode characters).
The arabic expression for “done” is “khallas”, which is used often enough in the region that it also becomes slang for non-arabic speakers like myself. This project however is not done, there are always many ways to improve such models. Instead, “yalla” is more appropriate here, which roughly means “let’s go”, and improve the models further!
Yalla let's go!