What's the entropy of a fair coin toss?
Marton Trencseni - Sat 25 September 2021 - Math
Introduction
I use a set of 20 screening questions for Data Science interviews. The questions are asked by my (non-technical) recruiter on the phone, so I wrote them so they have objective answers, like yes/no/0/1/42.
One of the questions goes like this:
Q: What is the entropy of a fair coin toss?
A: 1 bit
Then there is a follow-up:
Q: What is the entropy of a coin that is almost always heads?
A: 0 bits (or approximately 0 bits)
My recruiter reports that from a sample size of ~50 candidates, very few can answer these entropy related questions. So, why did I think these are good and relevant screening questions?
- Entropy is a common and useful concept in Data Science. Our current
datascience-maingit repo has 7 occurences of the stringentropyin our own code (not library code). - I learned about entropy in multiple classes during my Comp.Sci. degree (20 years ago).
- I learned about entropy in multiple classes during my Physics degree (20 years ago).
- I find entropy to be one of the most intellectually pleasing concepts, partially because it occurs across a wide array of disciplines.
So I'm writing this post to remind and excite ourselves about entropy.
What is entropy?
Per the Wikipedia page on Entropy:
Entropy is a scientific concept, as well as a measurable physical property that is most commonly associated with a state of disorder, randomness, or uncertainty. The term and the concept are used in diverse fields, from classical thermodynamics, where it was first recognized, to the microscopic description of nature in statistical physics, and to the principles of information theory.
If you then jump over to https://en.wikipedia.org/wiki/Entropy_(information_theory), it even has the answers:
.. and to communicate the outcome of a coin flip (2 possible values) will require an average of at most 1 bit (exactly 1 bit for a fair coin).
and
.. a double-headed coin that never comes up tails, or a double-tailed coin that never results in a head. Then there is no uncertainty. The entropy is zero: each toss of the coin delivers no new information as the outcome of each coin toss is always certain.
I'm not sure if I knew this when I wrote the questions, but the opening Wikipedia page has the answers.
What is the entropy of a fair coin toss?
Let's look at two ways to get the answers:
(1) Use the formula for information entropy (Shannon entropy), which is $ H(X) = - \sum_i P(X=i) log_2 P(X=i) $. For a coin where the probability of H is p, the shape of the entropy function is:
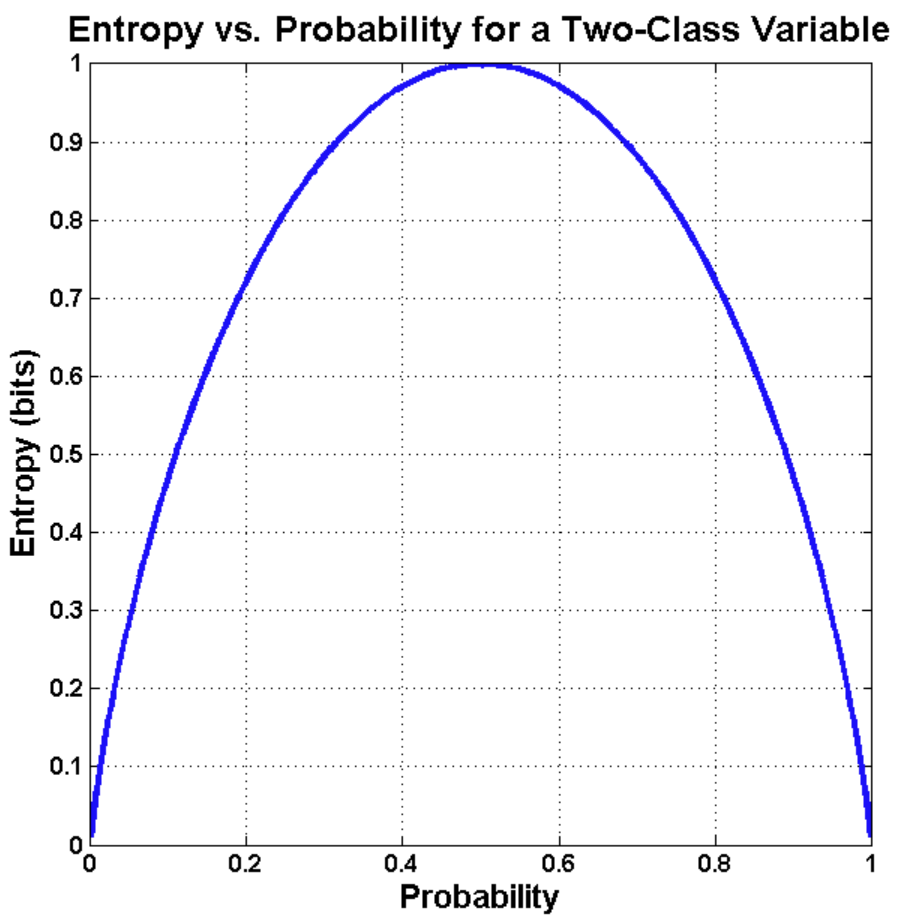
For a fair coin, we have two outcomes, both have $ P(X=H)=P(X=T)=\frac{1}{2} $, so $ H(X) = - [ \frac{1}{2} log_2\frac{1}{2} + \frac{1}{2} log_2\frac{1}{2} ] = 1 $. Since we're using base 2 logarithm, the result is in bits. For the coin that is almost always H or almost always T, both terms are zero, so the entropy is 0.
(2) Use intuition: the most untuitive way to think about entropy is this. Suppose there you have to transmit messages using 0 and 1 bits. The number of message types is the number of outcomes of the random variable $X$. So, for a random coin toss, there are 2 messages, H and T. Then, there is a daemon who randomly generates these messages according to the probabilities of $X$. The question is, what is the average minimum number of bits per message we can use to transmit messages coming from $X$? The answer is just $H(X)$, the entropy. So for a fair coin toss, we can encode H as 0, T as 1, and since both occur with equal chance, we can't get more efficient than that, so we need 1 bit. And if the coin always lands on either H or T, there is no randomness, we don't need to transmit anything, the other side already knows.
Let's strengthen our intuition by first deconstructing it and reconstructing it: the above 2 cases (1 bit and 0 bit entropy) are edge-cases, let's look at the "middle." What if H occurs $\frac{3}{4}$ of the time, and T occurs $\frac{1}{4}$ of the time? Per the formula above, $H(X) = 0.81 $. How can we go below 1 bit to transfer two possible outcomes? For the case of the "almost always H" coin, the answer was zero bits, but that was kindof cheating, because we don't need to send anything at all. How do we send 0.81 bits?
The answer is, we can encode multiple outcomes: since H is more likely than T, it makes sense to use less bits to encode HH than TT or even HT. We can do the following:
HH -> P(HH) = 9/16 -> encode as 0 (length = 1 bit )
HT -> P(HT) = 3/16 -> encode as 10 (length = 2 bits)
TH -> P(TH) = 3/16 -> encode as 110 (length = 3 bits)
TT -> P(TT) = 1/16 -> encode as 111 (length = 3 bits)
This code is a prefix code, which means that if $C_i$ is a codeword (like 0 or 10 in the above example), then $C_i$ never occurs as a prefix of another codeword $C_j$ (eg. above 0 is a code, and none of the other codes start with 0, 10 is also a code, and none of the others start with 10). So on the receiver end, if this code is used, it is always possible to unambigiously decode the series of 0s and 1s and get back the series of Hs and Ts. With the above code, we're using as average of $ 1\frac{9}{16} + 2\frac{3}{16} + 3\frac{3}{16} + 3\frac{1}{16} = \frac{27}{16} = 1.68 $ bits to transfer 2 messages, so 0.84 bits per message. So on average we're below 1 bit, although this coding is still about 0.03 bits higher than the entropy itself. We can further approach the theoretical limit set by the entropy by encoding longer sequences (eg. HHH, HHHH, etc). Note that this is not Huffman-coding, Huffman-coding would just assign 0 and 1 to H and T.
Entropy in Data Science
I will mention two areas where entropy pops up in everyday Data Science work:
(1) Splitting nodes during Decision Tree building: The first parameter for Scikit-learn's DecisionTreeClassifier is:
criterion {gini, entropy}, default=gini
> The function to measure the quality of a split. Supported criteria are
> gini for the Gini impurity and entropy for the information gain.
One of the ways to build Decision Trees is to look for splits such that the 2 child nodes have on average maximally lower entropy than the parent node. So, if for example the parent node has 10 data points labeled HHHHHTTTTT and splitting along attribute A yields two nodes with labels HHTTT and HHHTT, while splitting along attribute B yields two nodes with labels HTTTT and THHHH, then the second one is better, because it has lower average entropy (and hence higher information gain). See this post on TowardsDataScience for a full example.
(2) Cross-entropy as a loss function when training Deep Neural Networks: From the Wikipedia page for Cross entropy:
In information theory, the cross-entropy between two probability distributions p and q over the same underlying set of events measures the average number of bits needed to identify an event drawn from the set if a coding scheme used for the set is optimized for an estimated probability distribution q, rather than the true distribution p... Cross-entropy can be used to define a loss function in machine learning and optimization. The true probability p is the true label, and the given distribution q is the predicted value of the current model.
Not to be confused with:
Entropy in Physics
Entropy was originally invented/discovered in Physics in the 1800s, before Shannon re-discovered it for Information Theory 100 years later. Today it pops up all over physics: Thermodynamics, Statistical mechanics, Quantum physics, even in General relativity for black holes. The most famous occurence is the Second law of thermodynamics:
The second law of thermodynamics establishes the concept of entropy as a physical property of a thermodynamic system. Entropy predicts the direction of spontaneous processes, and determines whether they are irreversible or impossible, despite obeying the requirement of conservation of energy, which is established in the first law of thermodynamics. The second law may be formulated by the observation that the entropy of isolated systems left to spontaneous evolution cannot decrease, as they always arrive at a state of thermodynamic equilibrium, where the entropy is highest. If all processes in the system are reversible, the entropy is constant. An increase in entropy accounts for the irreversibility of natural processes, often referred to in the concept of the arrow of time.
The classic explanation goes like this: suppose we have a cylinder split in half with a thin divider. The left side has gas in it, the right side has no gas, it's a vacuum. If we remove the divider, the gas will quickly fill up the whole cylinder. The configuration with the gas constrained to the left side has lower entropy, since certain possibilities (eg. positions of molecules on the right cide) are not possible; this is like the coin that is heads $\frac{3}{4}$ of the time. The final spread out gas has higher entropy, this is like the fair coin. On a microscopic level, gas molecules can be thought of as billiard balls constantly colliding with each other and the wall. Under certain conditions we can assume that the collisions are elastic, which means everything is reversible. This means that if we record a video of the gas, and then it backwards, all the microscopic colisions that we see (happening backwards) are allowed by physics to happen [even if time is going forward]. So, if somebody shows us microscopic, zoomed in cideo footage of this gas, we can't tell if the tape is playing forward or backwards. However, if we are allowed to see the whole tape zoomed out (macroscopic), and we see that the gas is going from a low-entropy state to a high-entropy state, we know the tape is playing forward, while if we see the gas going from a high-entropy state to a low-entropy state, we know that the tape is playing backwards.
A stylized but more every-day version goes like this: imagine all the air molecules (oxygen, nitrogen, etc) in the closed room you're sitting in. Why doesn't all the gas spontaneously collect in the bottom left corner of your room [which would lead you to suffocate]? The other way it works: if we somehow collect all the air in one corner, and then let it go, it will spread out, but the opposite never occurs. This is essentially what the second law is saying: the possible set of configurations of air molecules in just one corner of the room has lower entropy than if the gas is spread out all over the room. So, spreading out naturally occurs all the time, while the reverse never happens. You can actually compute this by dividing the room into grids, and placing the air molecules in grids (also velocities), counting configurations, and approximating the entropy ratio.
Note: a lovely intellectual rabbit hole to go down: what about gravity? Gravity tends to pull things together, so does gravity decrease entropy?
See also:
Conclusion
Hopefully this post is a good reminder that entropy is a useful concept, or enough to get people interested. A good short refresher written by physicist Edward Witten is A Mini-Introduction To Information Theory. If you need a textbook refresher on entropy and information theory, the standard reference is: Cover, Thomas: Elements of Information Theory. I plan to write a follow-up post about Joint entropy, Conditional entropy, Kullback–Leibler divergence and Mutual information.