Building the Fetchr Data Science Infra on AWS with Presto and Airflow
Marton Trencseni - Wed 14 March 2018 - Data
Introduction
Our goal at Fetchr is to build a world-class Data Science team. To do this, we need a world-class Data Science platform. I was fortunate enough to work at Facebook previously, which over the years arrived at a very efficient way of doing Data Science. So, when it came to building the platform I decided to follow the basic design patterns that I saw at Facebook.
Based on the last 6 months, building a platform (including computation jobs, dashboarding) that is simple but allows us to move fast is feasible in just a 3-6 month period. So what does our platform look like? Like most things at Fetchr, we run on AWS. Our infra consists of 5-10 nodes right now (5 EMR, 2 Airflow, a few more for Supersets and others).
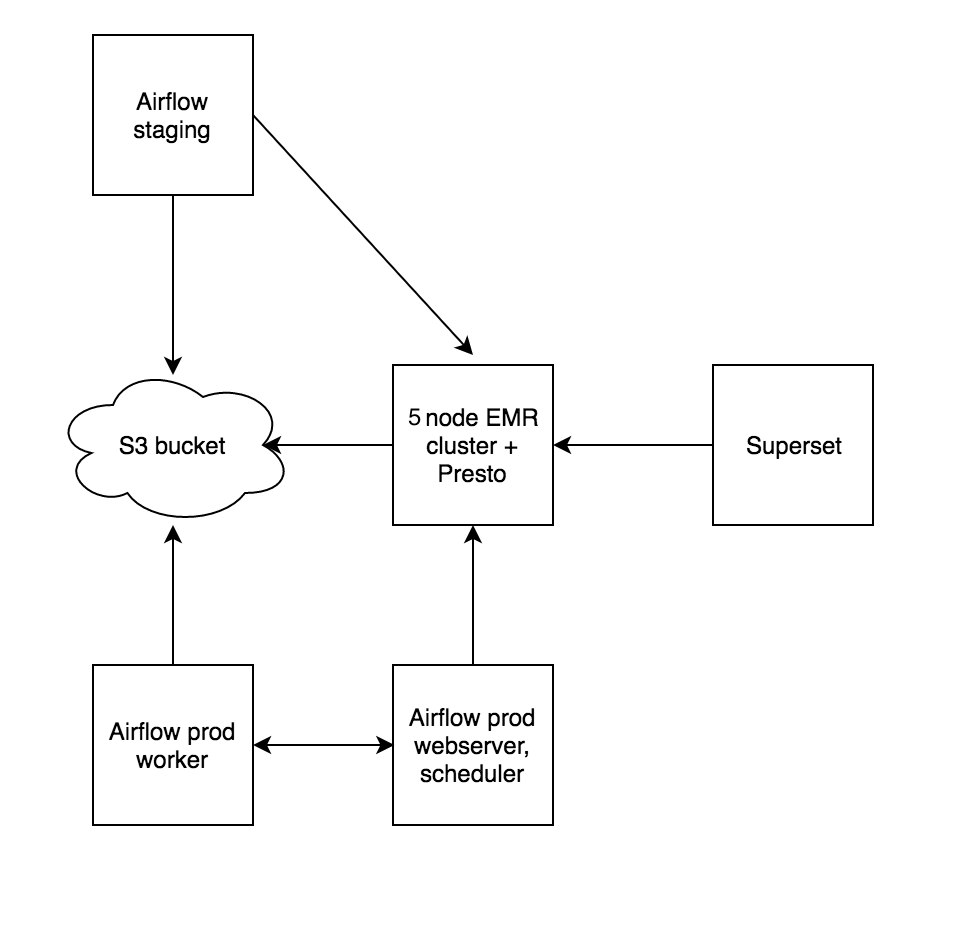
We use EMR to get a Hadoop instance, with S3 as the backing storage. We actually don’t use the Hive query engine or MapReduce. We just use Hadoop as a metadata store (table definitions) for Presto. Each EMR node also runs a Presto worker. Right now we use 1+4 nodes, with plans to scale it out to ~10.
The data warehouse (DWH) philosophy is again based on the Facebook design pattern. We use flat tables, no fact/dimension tables; usually you can look at a table and see a complete picture. This makes the tables very usable and allows us to move fast, for example writing quick queries against tables is easy because it doesn’t require a lot of JOINs to get readable strings.
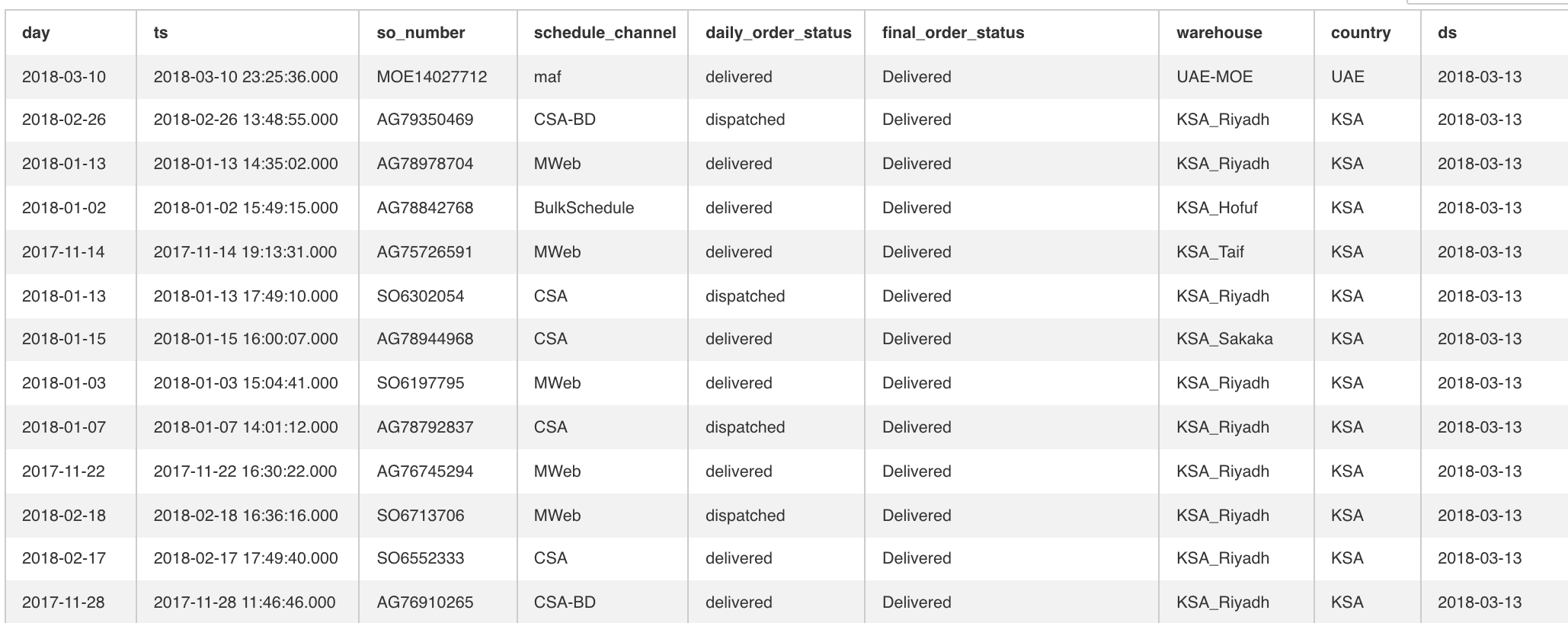
The other major design pattern from Facebook is the idea of daily partitioned tables. This is a feature available on Hive, and not really practical on eg. Redshift. Essentially we store (complete) daily, write-once slices of each table, which are generated by daily jobs. The partitions are called ds at Facebook and logically show up as a column of the table, and you’ll find plenty of references to it if you read the Hive docs (because Hive was written at Facebook). Physically, these are essentially directories, each one holding the data files for that day’s data. We use S3, so in our case it looks something like s3://dwh-bucket/<table>/<ds>/<data_files>. For example, s3://dwh-bucket/company_metrics/2018-03-01/datafile. For technical reasons, when importing data from our production (Postgresql) database, we use .csv, for later computed warehouse tables we use ORC.
The advantage of this is that we have a complete history of the data warehouse going back as far as we’d like (old partitions can be deleted from a script after the desired retention period expires). There’s two ways to use ds partitions, cumulative and events: each partition can store a complete copy of its data up to that day (cumulative), or each partition just stores that day’s worth of (event) data. For aggregate tables, it’s usually the first, for raw event tables, it’s usually the second. For example, our company_metrics has complete cumulative data in each ds, while our driver_telemetry table has just that day’s worth of telemetry events. The advantage of this is that if something breaks, there’s almost never a big problem; we can always refer to yesterday’s data, and get away with it. Data will never be unavailable, it may just be late. Also, if there’s ever a question why a number changed, it’s easy to see what the reported number was a month ago (by examining that day’s ds partition).
We use Airflow for data piping, which is loosely based on Facebook’s Dataswarm system. Airflow allows us to write jobs as Directed Acyclic Graphs (DAGs) of tasks, with each task getting something useful done, like a database INSERT. In Airflow, each DAG has a schedule, which uses the cron format, so it can be daily, hourly, or just run every Wednesday at 3:15PM. On each of these runs, Airflow creates an instance of the DAG (identified by the timestamp), and executes the tasks, taking into account the dependencies between them. We have 2 types of DAGs: imports, for importing tables from the production database to the DWH, and compute jobs, which take existing (imported or computed) tables and make a new, more useful table. Fundamentally, each table is its own DAG.
This poses a question: how do we make sure that a table’s DAG only runs once another table that is required (eg. it’s used in the FROM part) is available (the latest ds is available). This is accomplished with having special sensor tasks, which continuously check something (in this case whether a table’s partition is there), and only succeed if the check succeed; until then these “wait” tasks block the DAG from executing. For example, this is what a typical DAG looks like:
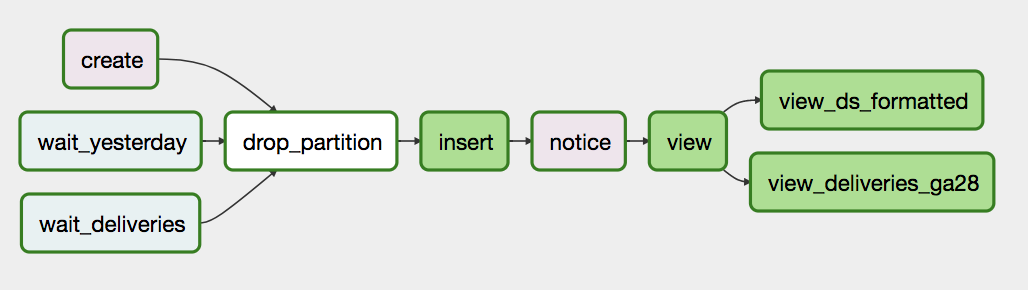
There are two waits (one for a table called deliveries, one for this table but yesterday’s ds partition, which is a kind of self-dependency), there is a create task which creates the table in case it doesn’t exist, the drop_partition drops the partition in case it already exists (in case we’re re-running the job), the insert does the actual INSERT INTO … SELECT ... FROM ..., and then some useful views are created (eg. for a table called company_metrics, the view task creates a view called company_metrics_latest, which points to the latest ds partition).
DAGs for import jobs are simpler:

The s3copy is the task which dumps the table from the production Postgresql into a local file and then copies it to S3, to the appropriate path. The notice lets Hive now that we “manually” created a new partition on the backing storage, and triggers the metadata store to re-scan for new partitions by issuing MSCK REPAIR TABLE <table>. (The notice in the upper DAG is actually not required, since it’s a Presto job.)
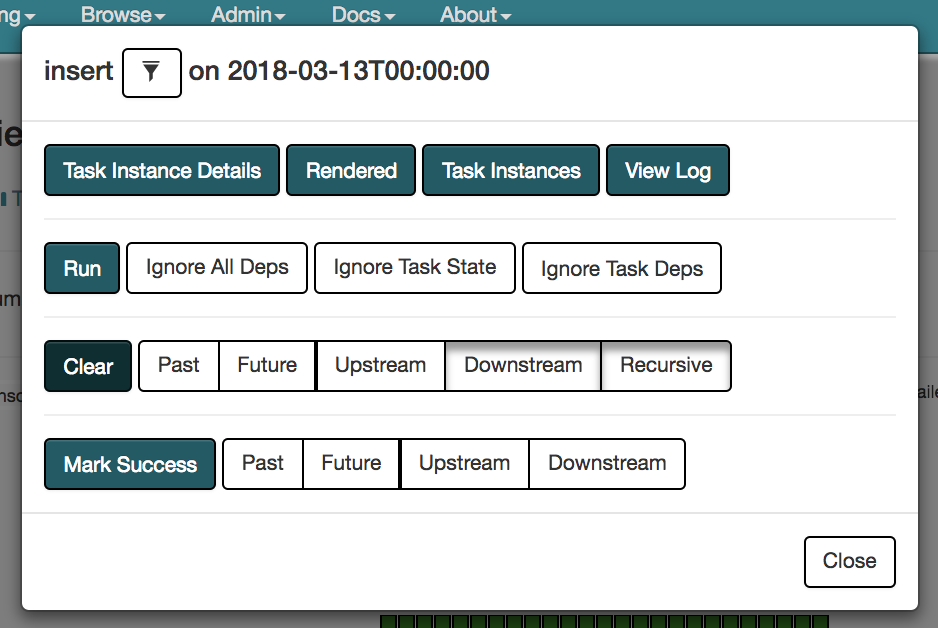
Airflow creates daily instances (for daily jobs) of these DAGs, and has a very helpful view to show progress/completion.
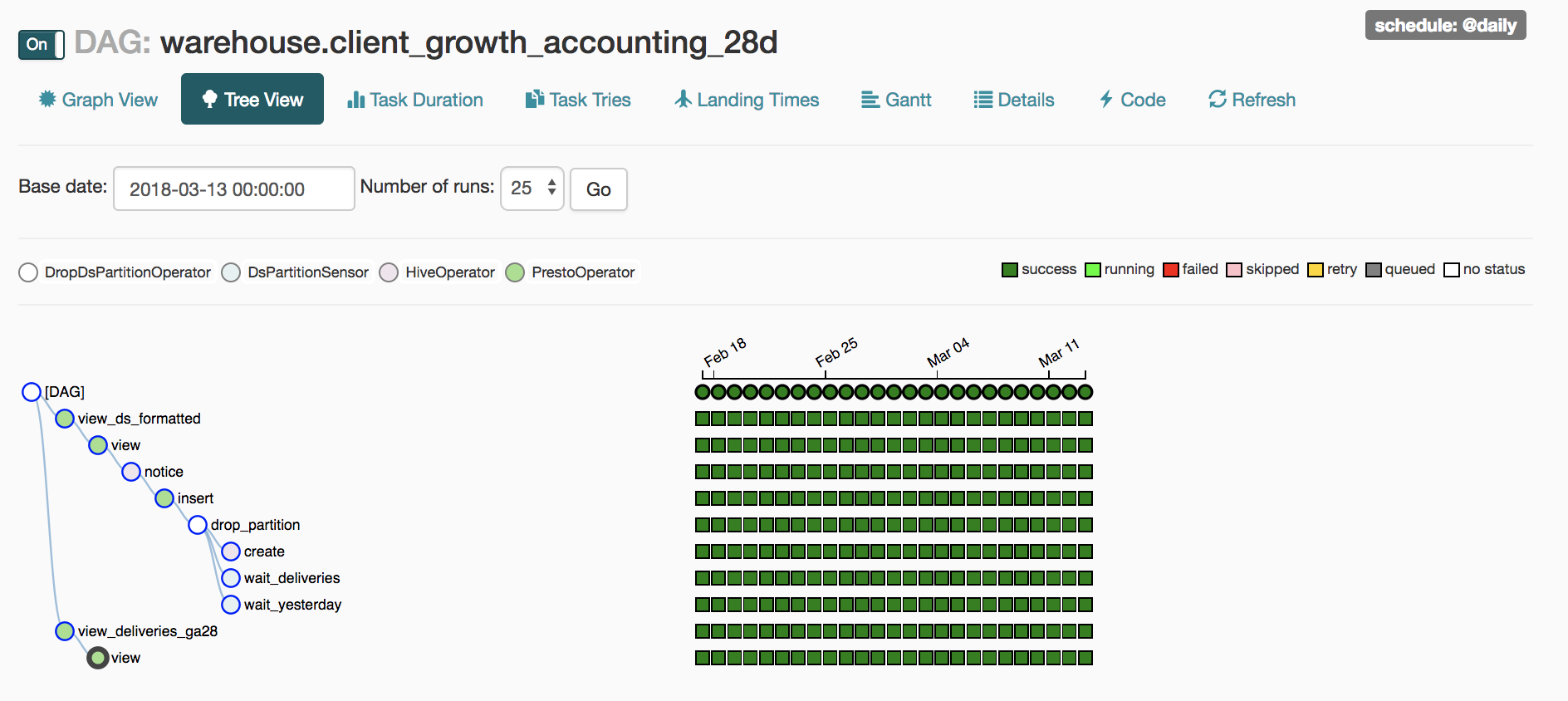
The UI also allows for tasks to be cleared, re-run, etc.
Each DAG is implemented as Python code, in our case one .py file per DAG. Most of these DAGs are highly repetitive, so we wrote a small library to save us time. For example, since we’re importing from a Postresql database, which is itself a relational database, it’s enough to say which table we want to import, our scripts figure out what the source table’s schema is, it knows how to map Postgresql types to Hive types, handle column names which are not allowed on Hive, etc. This makes importing a table as easy as:
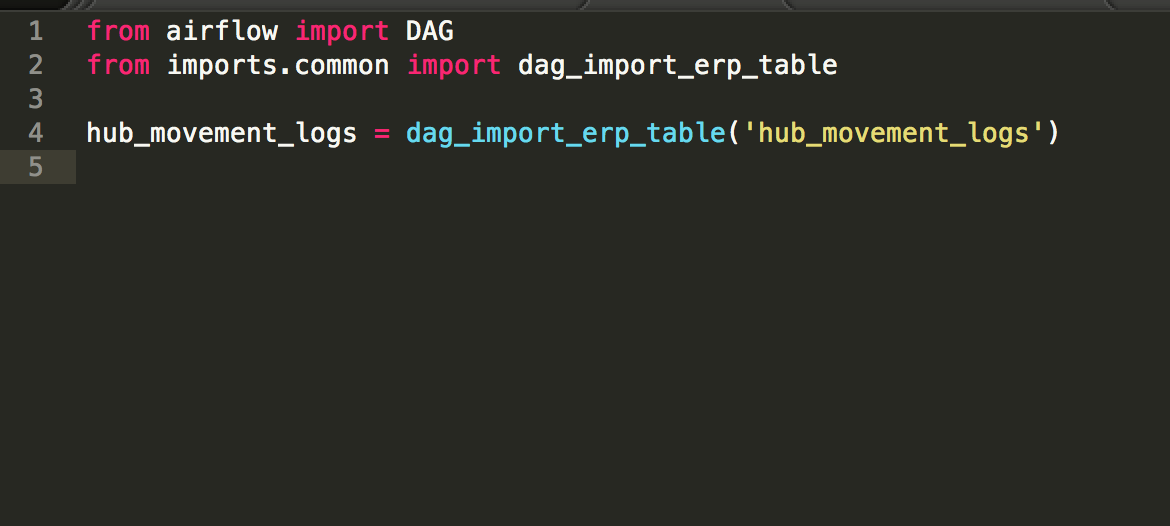
All the logic is contained in the dag_import_erp_table() function, which is re-used for all imports.
We wrote similar helper functions for our common warehouse jobs, which take existing tables to build a new, more useful one. We specify the name of the output table, the schedule_interval, the Hive columns (which is used to generate the CREATE TABLE task), and the Presto SELECT query, which will be placed after the INSERT part in the insert task. Note the use of the wait:: prefix in the FROM part. The helper functions automatically parses out these and generates wait tasks for these tables. A number of other such features were added to make it easy, fast and convenient to write jobs, without having to go outside the use of these helper functions. The {{ ds }} macro will be replaced by the Airflow runtime with the proper ds, like 2018-02-20.
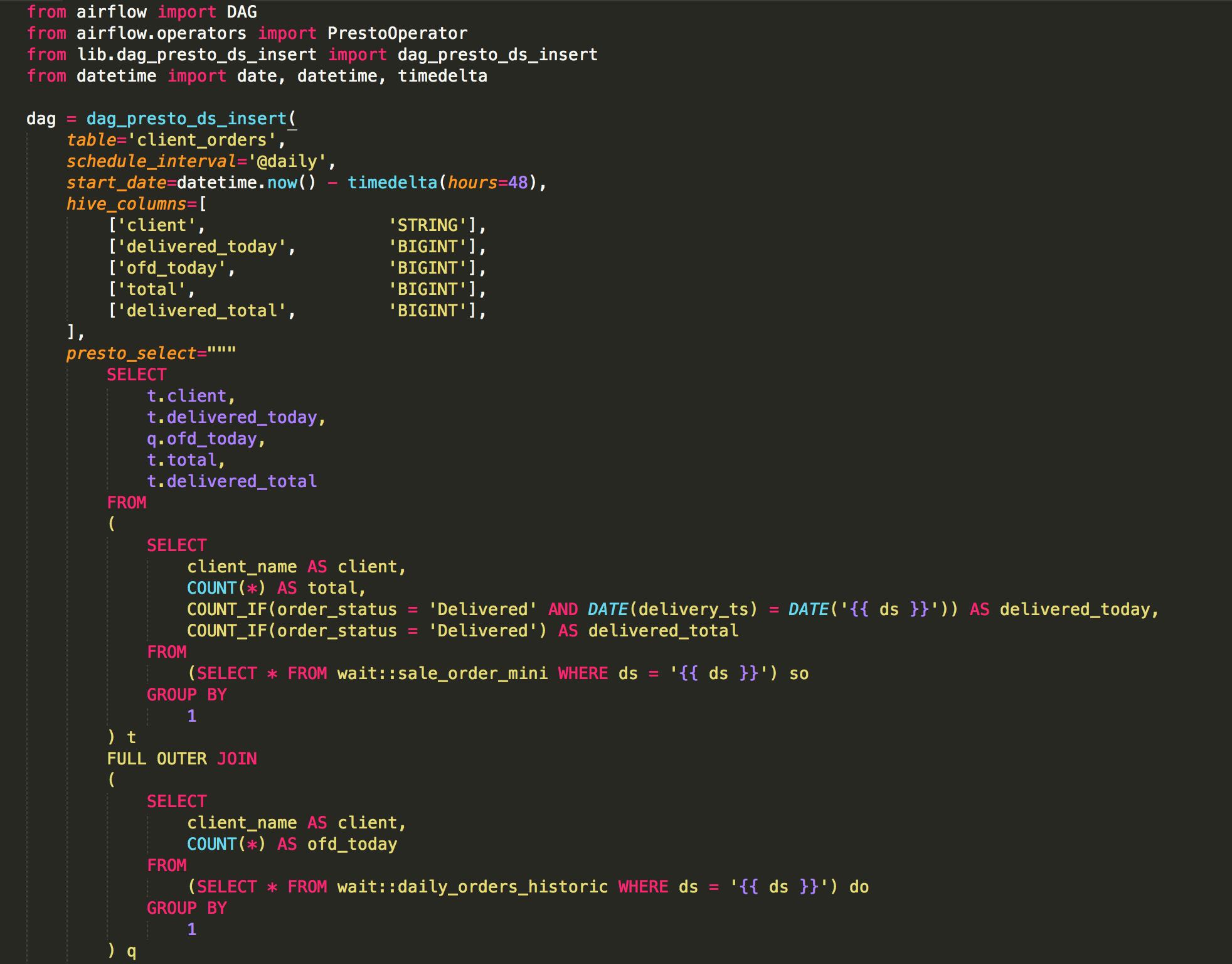
Right how we have around 50 jobs, about half are “real” computations, the rest are imports. At this point we are able to move really fast: writing a new job and deploying it to production takes about an hour, and new joiners can ramp up quickly. Because we use Presto/Hive on top of S3 (versus Airbnb runs their own Hadoop cluster) this introduced some low-level difficulties, so we had to write our own Operators, for example a PrestoOperator. Overall this code, plus the helper code is about 1-2k LOC, so it wasn’t too much work. To be fair, we never hit any data size problems, since compared to the capabilities of these tools, we have "small data". Our biggest tables are ~100M rows (these are part of 10-way JOINs), but Hive/Presto can easily handle this with zero tuning. We expect to grow 10x within a year, but we expect that naive linear scaling will suffice.
Maintaining a staging data warehouse is not practical in our experience, but maintaining a staging Airflow instance is practical and useful. This is because of Airflow’s brittle execution model: DAG’s .py files are executed by the main webserver/scheduler process, and if there’s a syntax error then bad things happen, for example certain webserver pages don’t load. So it’s best to make sure that scripts deployed to the production Airflow instance are already working. So we set up a second, staging Airflow instance, which writes to the same data warehouse, (we have only one) but has its own internal state. Our production Airflow instance runs on two EC2 nodes. One for the webserver and the scheduler, one for the workers. The staging runs on a third, all 3 components on the same host.
Overall, getting here was fast, mostly because:
- the database components (Hive, Presto) were open sourced by Facebook
- Amazon runs them for us as part of EMR
- we don't have to manage storage because of S3
- other former Facebook engineers built Airflow and Airbnb open sourced it
- because of the common background (Facebook) everything made sense.
Having said that, Airflow still feels very “beta”. It’s not hard to “confuse” it, where it behaves in weird ways, pages don’t load, etc. For example, if a DAG’s structure changes too much, Airflow seems to get confused and exceptions are thrown; for cases like this we wrote a custom scripts which wipes Airflow’s memory of this DAG completely (we didn’t find a way to do this with the provided CLI or UI). But, once we understood how it works and learned its quirks, we found a way to use it for our use-case. This process took about 1-2 months. We now rarely run into Airflow issues, perhaps once a month.
The limits of this architecture is that it's very batch-y. For "real-time" jobs, we use hourly or 15-minute jobs to get frequent updates, but we apply manual filters on data size to make these run fast(er). Overall, this is inconvenient, and won't scale very well, eventually we'll have to look at other technologies for this use-case. Overall, we feel this is inconveniance/limitation/techdebt is a small price to pay for all the high-level product and business impact that we were able to deliver with this architecture.
Airflow is now under Apache incubation, with lots of development activity, so it will surely get even better in the coming years. Going with Airflow was a bet that payed off, and we expect that Airflow will become the defacto open source ETL tool, if it’s not already that.
In the next part about Fetchr's Data Science Infra, I’ll talk about how we use Superset for dashboarding and SQL.