More Data Scientists should learn SQL
In my experience, many Data Scientists struggle to write SQL queries in interviews.
In my experience, many Data Scientists struggle to write SQL queries in interviews.
Marton Trencseni - Fri 23 July 2021 • Tagged with data, fallacies
What are the core skills a data scientist needs to sustainably achieve bottom-line impact, without blocking on external help from other roles?

Marton Trencseni - Fri 30 October 2020 • Tagged with stats, data
Sometimes we look at the top performers in a field and see obviously uneven representations of groups (gender, ethnicity, etc). There a multitude of factors that can lead to it, such as unfair bias in access to opportunities. Here I will show one unintuitive mathematical effect that can contribute to such unevenness in the case of normal distributions.
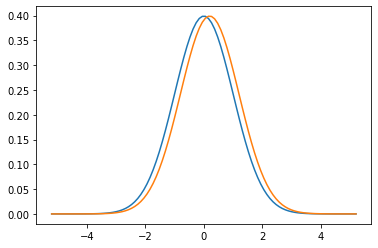
Marton Trencseni - Tue 01 September 2020 • Tagged with charts, dashboards, data, visualization
Most charts should be line charts or stacked area chart, because they communicate valuable trend information and are easy to parse for the human eyes and brain.
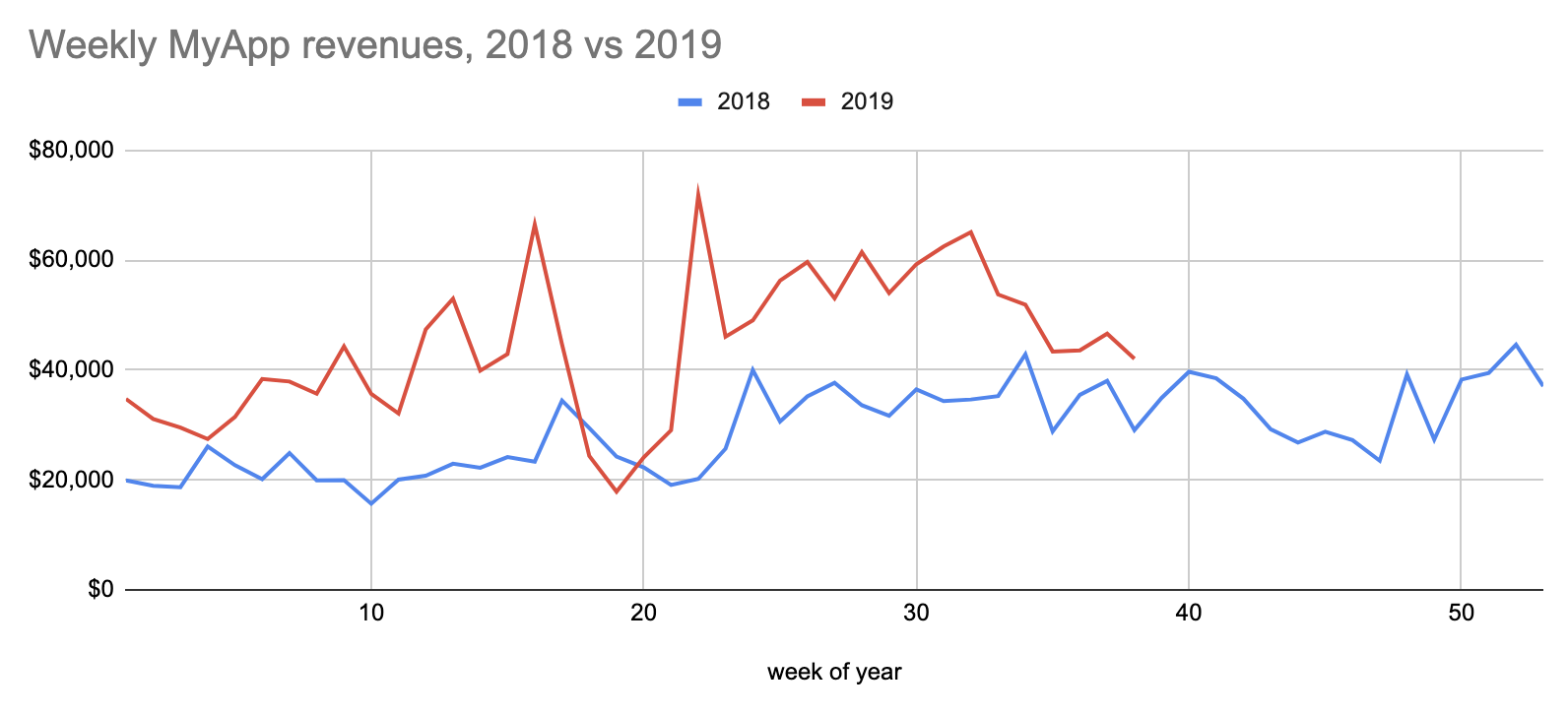
Marton Trencseni - Sun 23 August 2020 • Tagged with charts, dashboards, data, visualization
Format numbers for human consumption. What is more readable, 1.539e+5 or 153,859? Showing numbers effectively on spreadsheets, charts, dashboards, reports is a basic ingredient for readability, like formatting code in programming.

Marton Trencseni - Sat 22 August 2020 • Tagged with charts, dashboards, data, visualization
Making clear, readable charts is part of the craftmanship minimum for any data related role. In part one, I look at how to present categorical data.
Marton Trencseni - Thu 06 February 2020 • Tagged with data, ab testing, statistics
In the previous post, I talked about the importance of the Central Limit Theorem (CLT) to A/B testing. Here we will explore cases when we cannot rely on the CLT to hold.
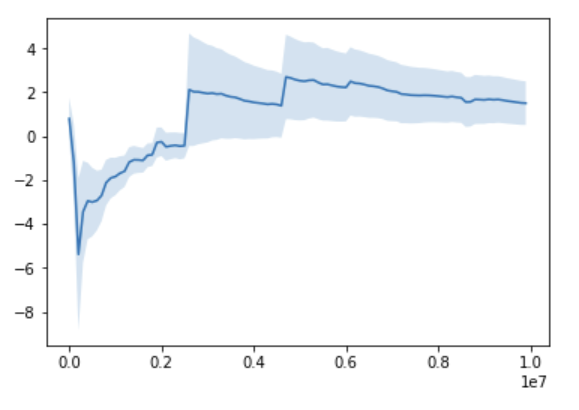
Marton Trencseni - Wed 05 February 2020 • Tagged with data, ab testing, statistics
When working with hypothesis testing, the desciptions of the statistical method often has normality assumptions. For example, the Wikipedia page for the z-test starts like this: "A Z-test is any statistical test for which the distribution of the test statistic under the null hypothesis can be approximated by a normal distribution". What does this mean? How do I know it’s a valid assumption for my data?
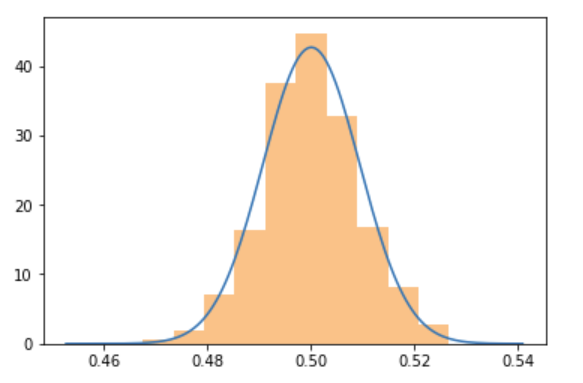
Marton Trencseni - Sat 01 February 2020 • Tagged with data, airflow, python
Sometimes I get to put on my Data Engineering hat for a few days. I enjoy this because I like to move up and down the Data Science stack and I try to keep myself sharp technically. Recently I was able to spend a few days optimizing our Airflow ETL for speed.
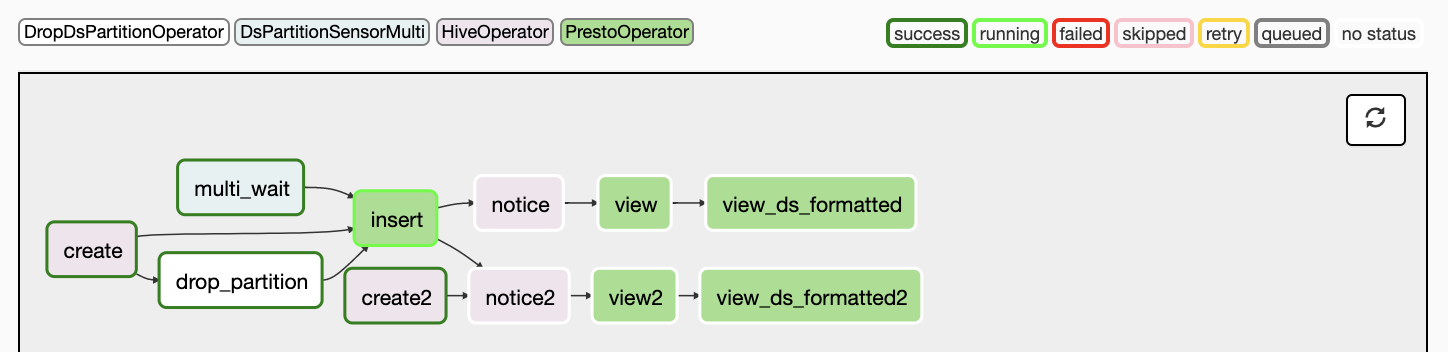
Marton Trencseni - Sun 26 January 2020 • Tagged with data, programming, sql
My list of SQL best practices for Data Scientists and Analysts, or, how I personally write SQL code. I picked this up at Facebook, and later improved it at Fetchr.

Marton Trencseni - Fri 24 January 2020 • Tagged with data, programming, sql
This is a simple post about SQL code formatting. Most of this comes from my time as a Data Engineer at Facebook.

Marton Trencseni - Thu 29 August 2019 • Tagged with data, fetchr
The idea is simple: write a document which helps new and existing people—both managers and individual contributors—get an objective, metrics-based picture of the business. This is helpful when new people join, when people start working in new segments of the business, and to understand other parts of the company.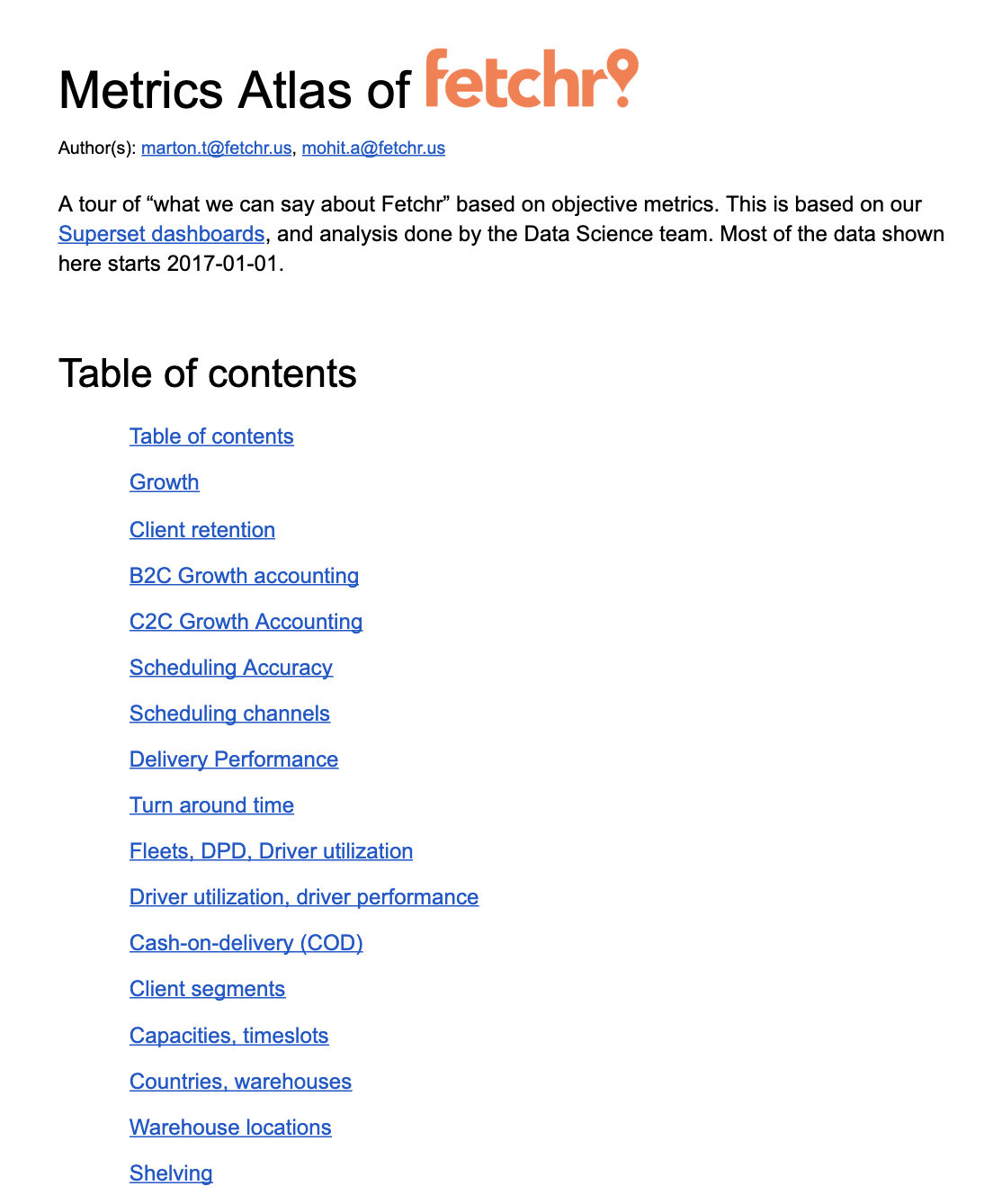
Marton Trencseni - Wed 09 January 2019 • Tagged with data, openai, waymo, deepmind, tesla, reinforce
2018 was a hot year for Data Science and AI. Here we picked out 5 highlights, which in our opinion shaped the field in the past year.
Marton Trencseni - Wed 26 September 2018 • Tagged with data, data-science, metrics, fetchr
Sometimes, the seven gods of data science, Pascal, Gauss, Bayes, Poisson, Markov, Shannon and Fisher, all wake up in a good mood, and things just work out. Recently we had such an occurence at Fetchr, when the Operational Excellence team posed the following question: if we could pick our Saudi warehouse locations, where would be put them? What is the ideal number of warehouses, and, what does ideal even mean? Also, what should our “delivery radius” be?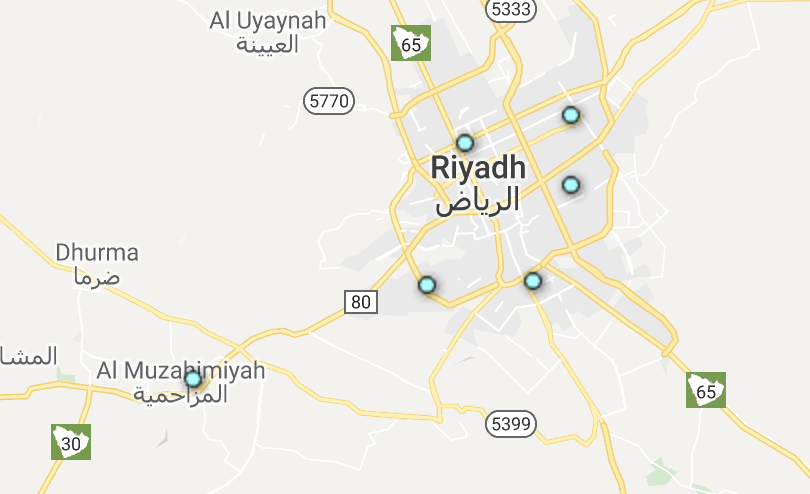
Marton Trencseni - Sun 16 September 2018 • Tagged with data, data-science, metrics, growth-accounting, fetchr
Previously I wrote two articles about data infra and data engineering at Fetchr. This time I want to move up the stack and talk about a simple piece of metrics engineering that proved to be very impactful: Growth Accounting and Backtraced Growth Accounting.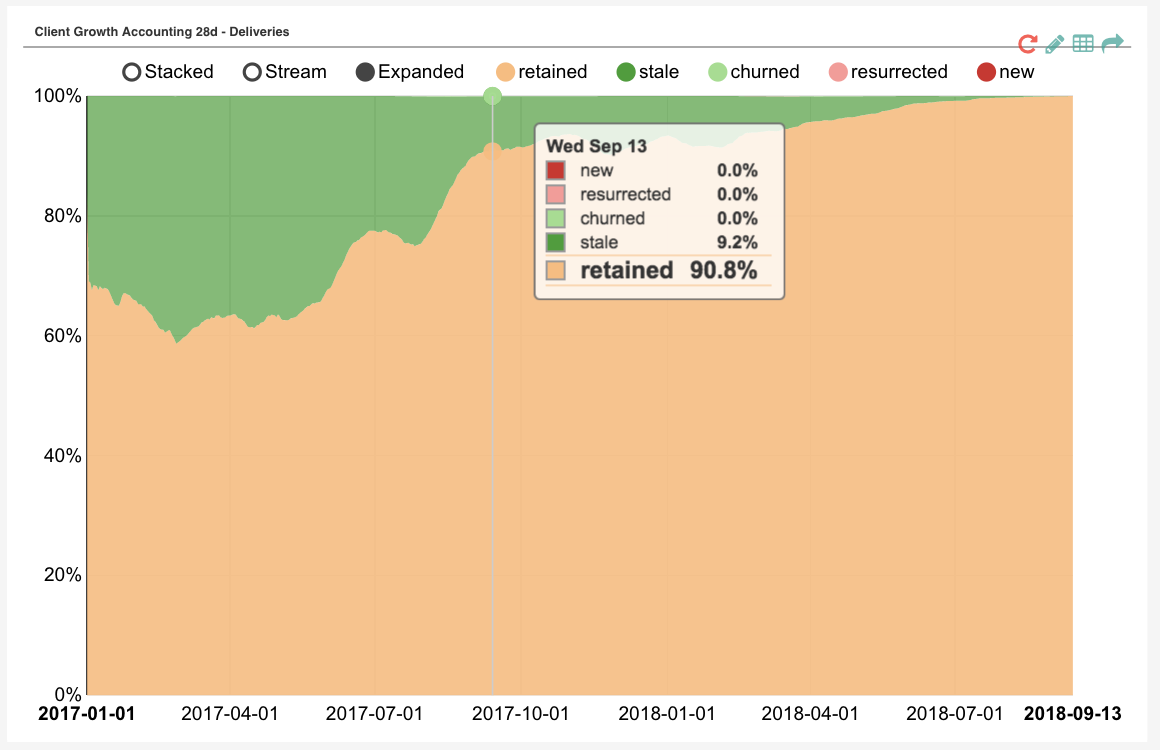
Marton Trencseni - Tue 14 August 2018 • Tagged with data, etl, workflow, airflow, fetchr, model, ml
A description of our Analytics+ML cluster running on AWS, using Presto, Airflow and Superset.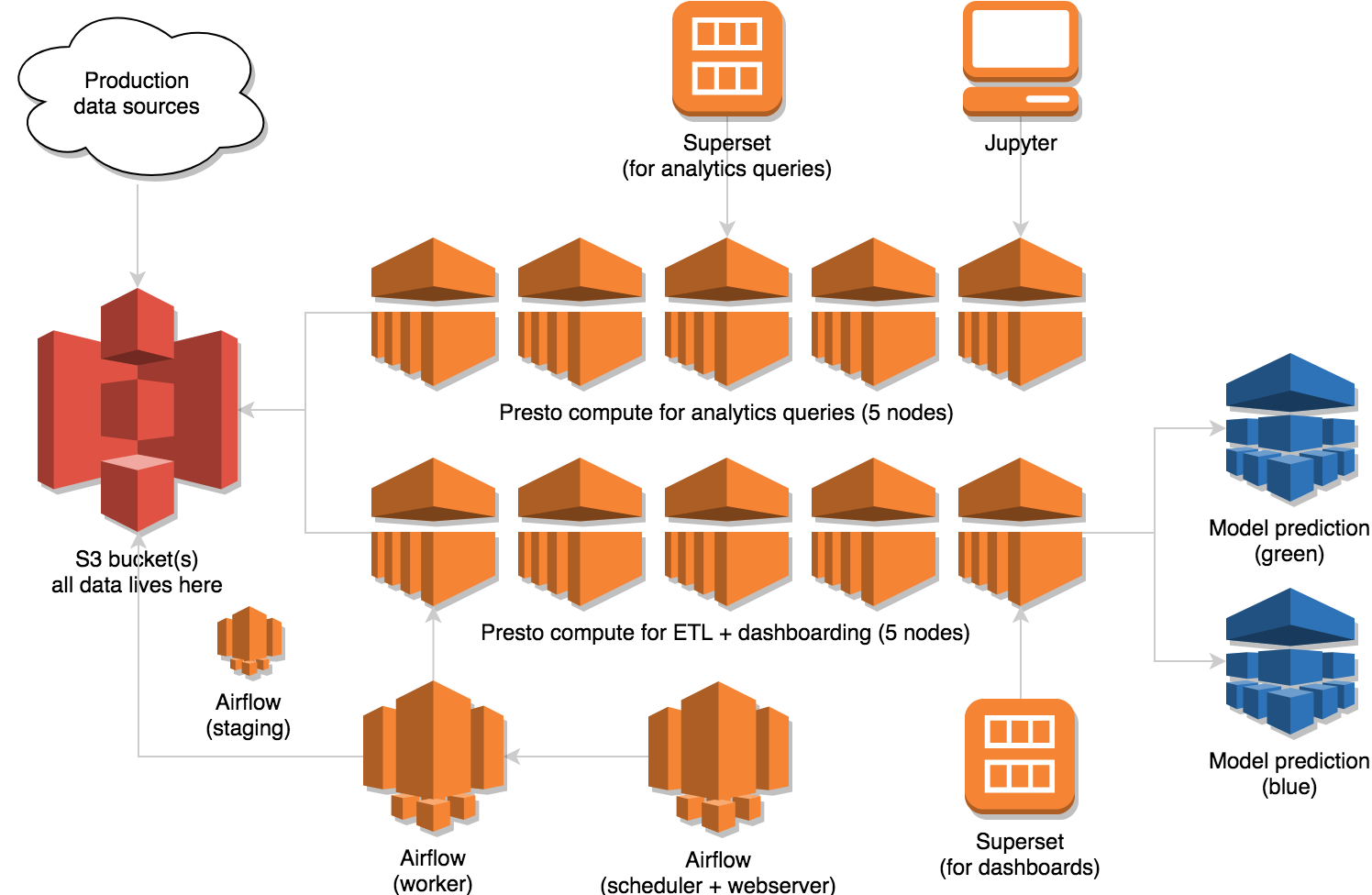
Marton Trencseni - Sat 07 July 2018 • Tagged with statistics, data
When working with averages, we have to be careful. There are pitfalls lurking to pollute our statistics and results reported.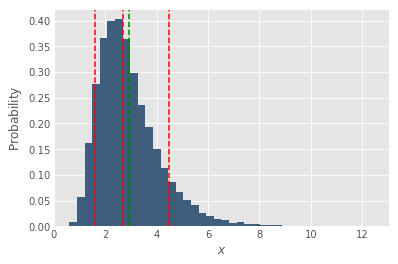
Marton Trencseni - Wed 14 March 2018 • Tagged with data, etl, workflow, airflow, fetchr
We used Hive/Presto on AWS together with Airflow to rapidly build out the Data Science Infrastructure at Fetchr in less than 6 months.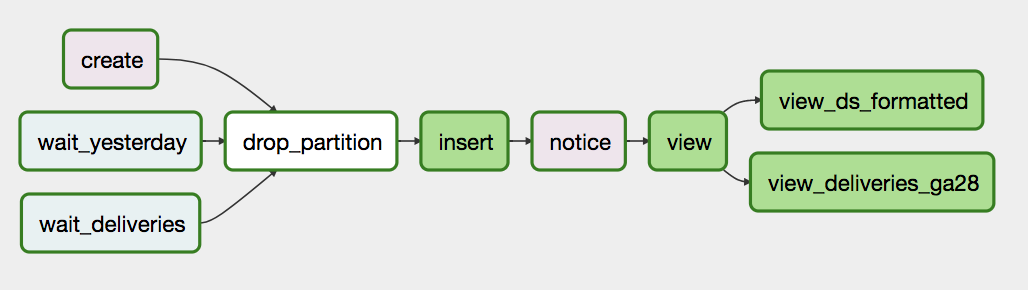
Marton Trencseni - Wed 09 November 2016 • Tagged with data, science, product, analytics
I used to think that a good analogy for using data is the instrumentation of a cockpit in an airliner. Lots of instruments, and if they fail, the pilot can’t fly the plane and bad things happen. There’s no autopilot for companies. The problem with this analogy is that planes aren’t built in mid-air. Product teams and companies constantly need to build and ship new products.
Marton Trencseni - Sun 05 June 2016 • Tagged with ab-testing, strata, statistics, data
I gave this talk at the O’Reilly Strata Conference London in 2016 June, mostly based on what I learned at Prezi from 2012-2016.