Fetchr Data Science Infra at 1 year
Marton Trencseni - Tue 14 August 2018 - Data
Introduction
This is a quick follow-up to my previous post describing the Fetchr Data Science infra and philosophy. The platform has doubled in the last 6 months, and I'm currently approaching the end of my first year at Fetchr, so it's a good time to post an update.
The basic principles behind our infrastructure have not changed, but we have scaled it out horizontally in key areas. We have also added a small ML prediction cluster, which is already in production and having a big impact on on-the-ground operations. As of today, the Data Science infra is about 20 nodes and looks like this:
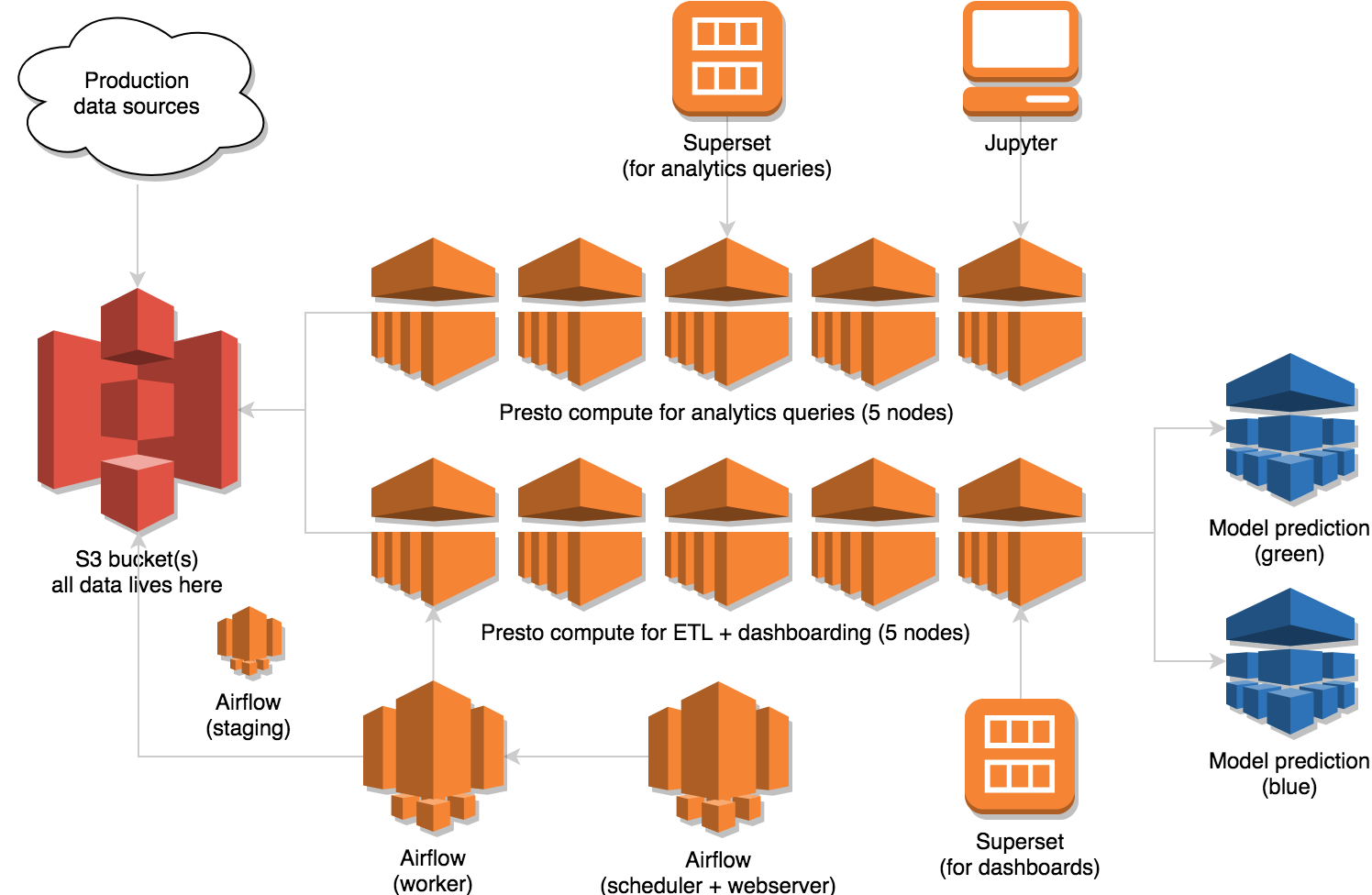
Architecture:
- S3 buckets (all data lives here)
- two Presto clusters
- 5 node Presto cluster for ETL and dashboards
- 5 node Presto cluster for analytics queries
- Airflow
- 1 node for scheduler + webserver
- 1 node for workers
- 1 node for staging
- Superset
- 1 node for dashboarding
- 1 node for analytics queries
- Jupyter host (Machine Learning notebooks)
- 2 node ML prediction cluster (blue+green)
S3
As before, all data lives on S3, whether it's data imported from our production databases or data produced by the ETL. Data imported is stored in flat CSV files, whereas DWH tables produced by Airflow running Presto jobs are stored in ORC format (like at Facebook). EMR/EC2 nodes never store data.
We continue to use the ds partitioned DWH architecture. This means that every night the ETL imports a fresh copy of all production tables into a new ds partition, like ds=2018-08-01, and all subsequent tables are also re-created in a new partition. Because all tables are backed on S3, this is also mirrored in our S3 path hierarchy. For example, the backing files for our main company_metrics table are divided like this:
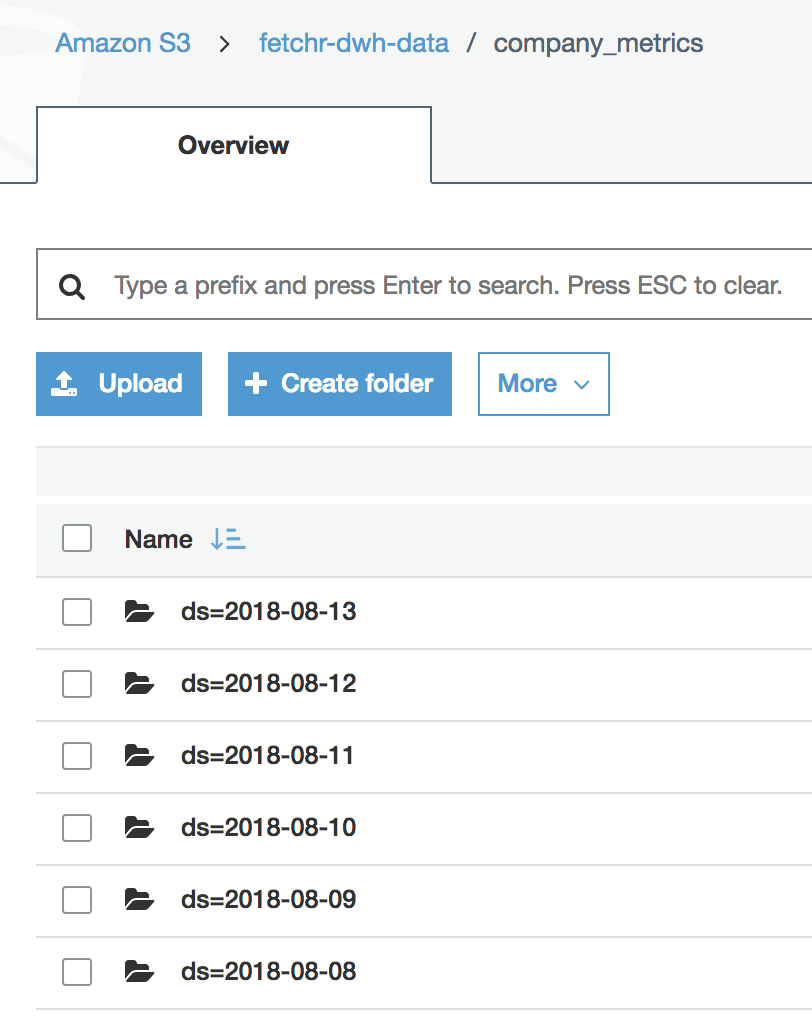
When querying, we always specify the ds like WHERE ds='2018-08-13', otherwise we're looking at multiple copies of the table. This is cumbersome, so for most of our tables, the Airflow jobs create a xyz_latest view that just points to the latest partition, like CREATE OR REPLACE VIEW xyz_latest AS SELECT * FROM xyz WHERE ds = '{{ ds }}'. This way analysts can usually just query the _latest and not think about it.
There are many upsides to this scheme: (i) if today's ETL fails, people can continue working with yesterday's data and (ii) since partitions are write-once, data never changes, so it's always easy to reproduce a number sent out 6 months ago (just run the query on that ds partition, like WHERE ds='2018-02-08'). The downside is that it's a lot of duplicate data, but with S3 being super-cheap this is a non-issue.
Okay, but still, this is wasteful and slow in terms of ETL time? After all, we just imported all these tables last night, do we need to re-import the whole dataset again? As the company and our data volume grew, the nightly import actually started taking too long, so we were forced to optimize this: for our big tables, now we import the historic tail once a week on weekends, and on a daily basis we only import data on orders that we received in the last ~3 months. This ensures our ETL finishes on time every night.
Presto
We currently run two EMR+Presto clusters, each 5 nodes. As before we don't run any ETL or queries on Hive/MapReduce, we exclusively use Presto for compute, since our queries never touch more than 10-100M rows.
We introduced a secondary cluster for ad-hoc analytics queries because, in cases when our ETL is slow and running during the day, or our regular hourly ETLs are running during the day, it kept blocking us from getting our work done.
Since all our data lives in S3, having two clusters see (read and write) the same data is not very hard. All we had to do is make sure our schemas are in sync on the two clusters. Since 99% of our schema operations are managed through Airflow jobs (CREATE TABLE IF NOT EXISTS ...), we just had to modify our Airflow framework to also execute these on the secondary cluster. Additionally, when we manually make changes to an existing table (ALTER TABLE ...), we have to execute this on both clusters, which is an inconvenience, but a minor one, and quite managable at this scale.
Airflow
We continue to use Airflow to be the backbone of our data pipelines with great success. We have two nodes for production: one running the scheduler and webserver, and one running the worker processes. Since these nodes don't do any compute themselves (they just launch Presto INSERT INTO ... SELECT jobs), we did not need to scale out here so far, nor do we expect this to happen in the next year.
One the other hand, we have deepened our investment into Airflow as our standard ETL system wrt code. We have identified the 4-5 common Airflow use-cases we have (import from Postgres to S3, run an ETL job on Presto, export data to the BI team's Redshift DWH, create dashbord screenshots and send in email, run Growth Accounting) and we have created helper functions to encapsulate them. As a result, the vast majority of our Airflow DAGs don't create Airflow operators directly, instead they call these library functions, which construct and return the DAGs. As a result our Airflow jobs look very clean, with all of the messy complexity hidden away:
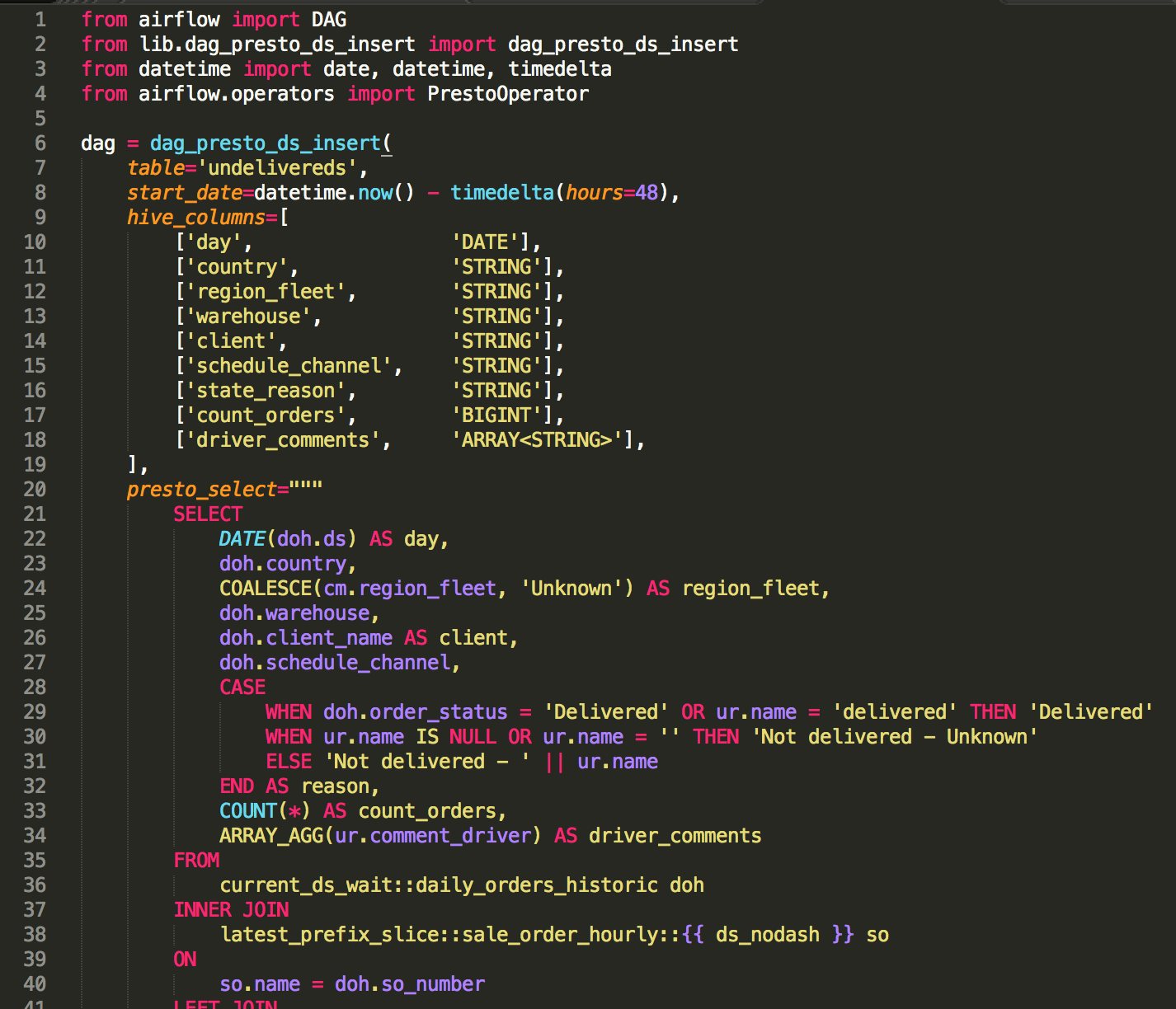
This had a big pay-off when we introduced our secondary Presto cluster a few months ago, and we needed to automtically create all our schemas there. We just added extra operators to our library functions to run schema operations on the secondary, and the next night when the ETL ran, all our table schemas were created on the secondary Presto cluster, pointing to the backing S3 files, ready to go. We were running analytics queries on the secondary cluster the day after we spun it up!
Currently we have 76 DAGs in Airflow, importing and exporting from 5-10 data sources (3 production databases, S3, 2 Presto clusters, Redshift, DynamoDB, various custom extracts sent to clients and the ML cluster).
Superset
Superset is both a dashboarding system and has an SQL IDE (called SQL Lab), which our Data Scientists use as their primary tool for accessing data. We continue to use Superset for dashboarding and have spun up a secondary Superset instance just for queries.
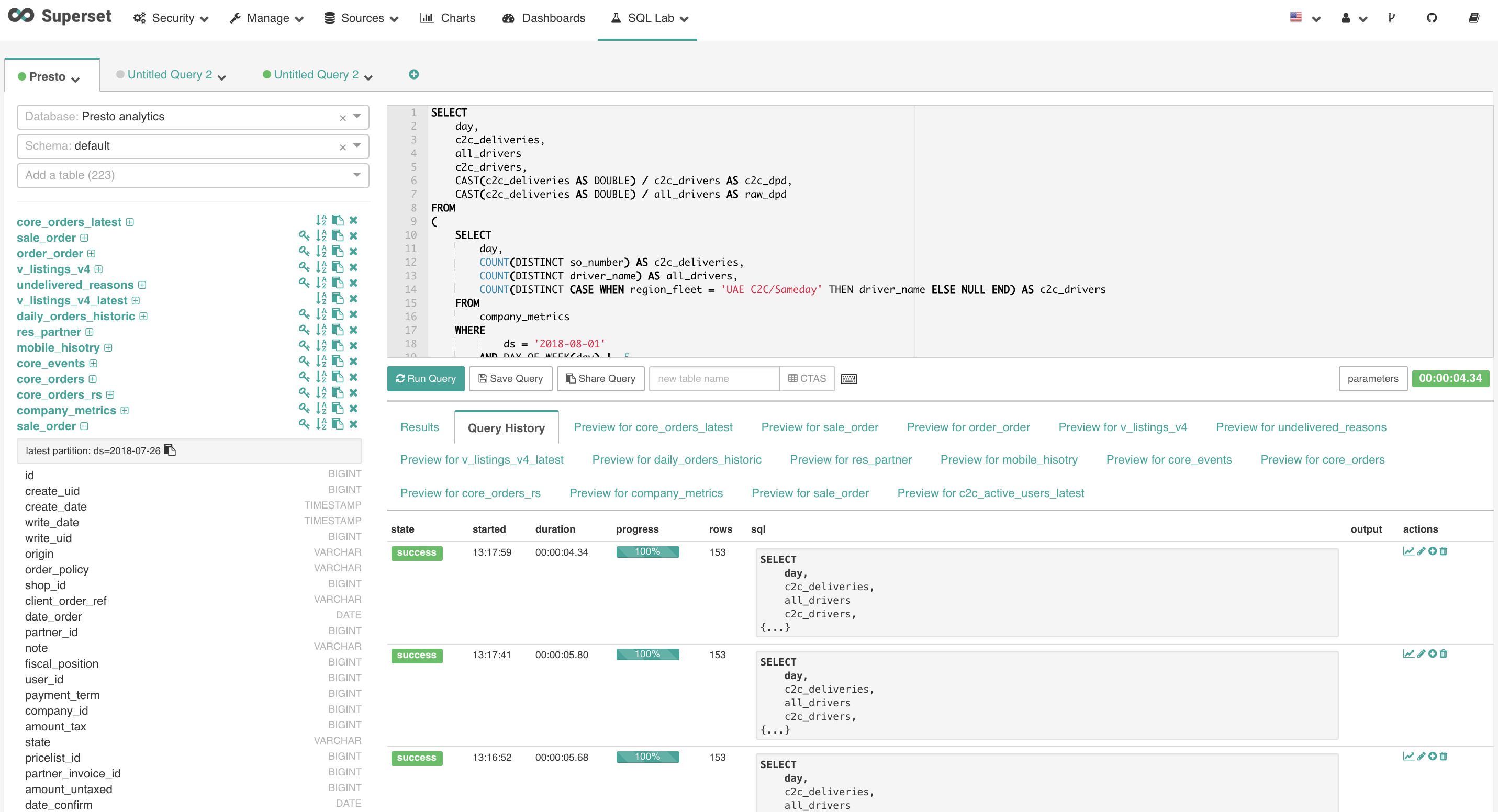
We have hit a limitation with Superset, where Superset will launch a new gunicorn process for each page request, and if the page happens to be a dashboard, for each chart on the dashboard. The chart processes will launch a Presto query each, which could take 10-60 seconds to return. Some of our dashboards have a lot of charts on them (20+), plus we have many concurrent users accessing dashboards (or running queries). In cases like this, Superset runs out of worker processes, and it becomes totally unresponsive. Each worker process eats up 1-2G of RAM, so the number of processes it can run are limited.
As an initial workaround, we split the dashboarding and querying use-case into two Superset instances, so analysts are not blocked by the dashboards. Additionally, we broke large dashboards into smaller pieces (which is unfortunate). This way, running 32 worker processes each, both instances are good for every-day work at current loads.
Both Airflow and Superset are still rough around the edges, but since Superset is user-facing, it can create more problems. It still happens that we want to look at a dashboard but the webserver times out because Superset ran out worker processes (maybe because the Presto queries are slow, because they're running on the same cluster as the ETL, and the ETL is slow, because something changed in production). Right now we get by with work-arounds (for example, in the previous case, we re-direct the Superset dashboarding traffic to the analytics cluster temporarily by changing a connection string, until ETL finishes). So far Superset is good enough for internal Data Science / Understand dashboards, and we do have a fair number of colleagues using it on a daily basis for basic reporting. But admittedly we will need to invest more time into understanding how to tune if we want to deploy it to a company-wide 1000+ person audience and feel good about it.
Currently we have 26 dashboards in Superset, many of them viewed by CxOs and country General Managers every day.
Machine Learning
In the last 3 months we have rolled out a prediction model in production. We perform the Data Science work to arrive at the models on our laptops and/or on a dedicated Jupyter host, in ipython notebooks. Once we're happy with the result, we deploy the model to our ML prediction cluster. We don't yet have CI/CD set up for it, deployment is manual and requires domain knowledge.
The model is already running in production and is being used for on-the-ground delivery operations, so downtime is not acceptable. We quickly arrived at a 2 node blue/green model: both nodes are running identical code/data, we deploy to green first, if it goes well, then to blue. Both are behind an Elastic Load Balancer (predict happens over a HTTP API call), so things keep going if one of them is down, even if down for a long time.
Fresh data is loaded every night by an Airflow process: first it creates a daily dump for the ML models, uploads it to S3, and then triggers a special load API call, first on the green, then the blue host. The Airflow job for blue depends on green, so if green fails, it won't touch blue, so production will not be impacted.
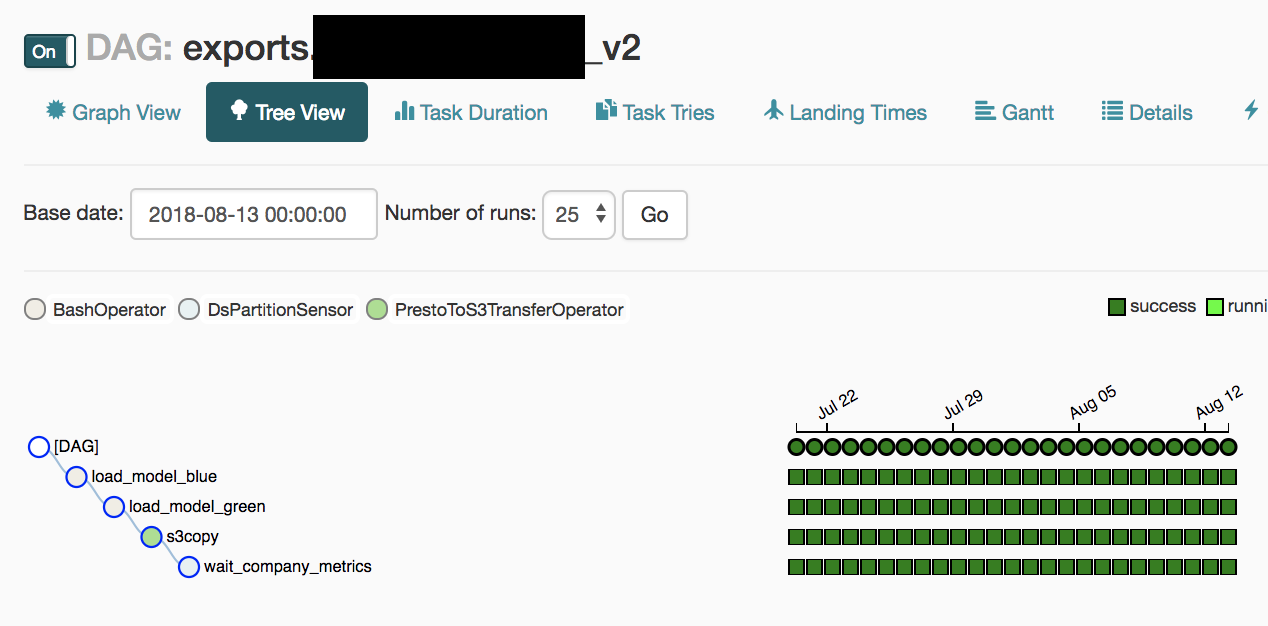
At this scale/complexity, this simple model works quite well and we have excellent uptime; we have more problems coming from software bugs than availability.
Impact
This post focused on what is usually called Data Infrastructure and Data Engineering, but actually to build and run this platform only took about 0.5-1 FTE average effort over time (though very senior FTEs). The rest of our time directly focused on operational and business impact by building metrics and dashboards, running ad-hoc analytics, building operational models for forecasting and sizing, building ML models, and most important of all, explaining it all to our colleagues so our work is adopted and has impact on the ground. It's interesting to note that just 5 years ago, in a similar scenario, good-enough open source tools like Airflow and Superset were not available, so we had to roll our own and ended up spending an order of magnitude more time on DI/DE work.
Overall, in the last year, our small Data Science team was able to have dollar-measurable outsized impact on Fetchr by using data to understand and optimize operations and business processes. Today, many important operational decisions are based on data and driven by Data Scientists, including sizing our fleets and warehouses, understanding their performance, and ML models optimizing and automating human labor.