Airflow review
Marton Trencseni - Wed 06 January 2016 - Data
Introduction
Airflow is a workflow scheduler written by Airbnb. It supports defining tasks and dependencies as Python code, executing and scheduling them, and distributing tasks across worker nodes. It supports calendar scheduling (hourly/daily jobs, also visualized on the web dashboard), so it can be used as a starting point for traditional ETL. It has a nice web dashboard for seeing current and past task state, querying the history and making changes to metadata such as connection strings. I wrote this after my Luigi review, so I make comparisons to Luigi throughout the article.
Note: Airflow has come a long way since I wrote this. Also, I've been using Airflow in production at Fetchr for a while. Check out Building the Fetchr Data Science Infra on AWS with Presto and Airflow.
Architecture
Airflow is designed to store and persist its state in a relational database such as Mysql or Postgresql. It uses SQLAlchemy for abstracting away the choice of and querying the database. As such much of the logic is implemented as database calls. It would be fair to call the core of Airflow “an SQLAlchemy app”. This allows for very clean separation of high-level functionality, such as persisting the state itself (done by the database itself), and scheduling, web dashboard, etc.
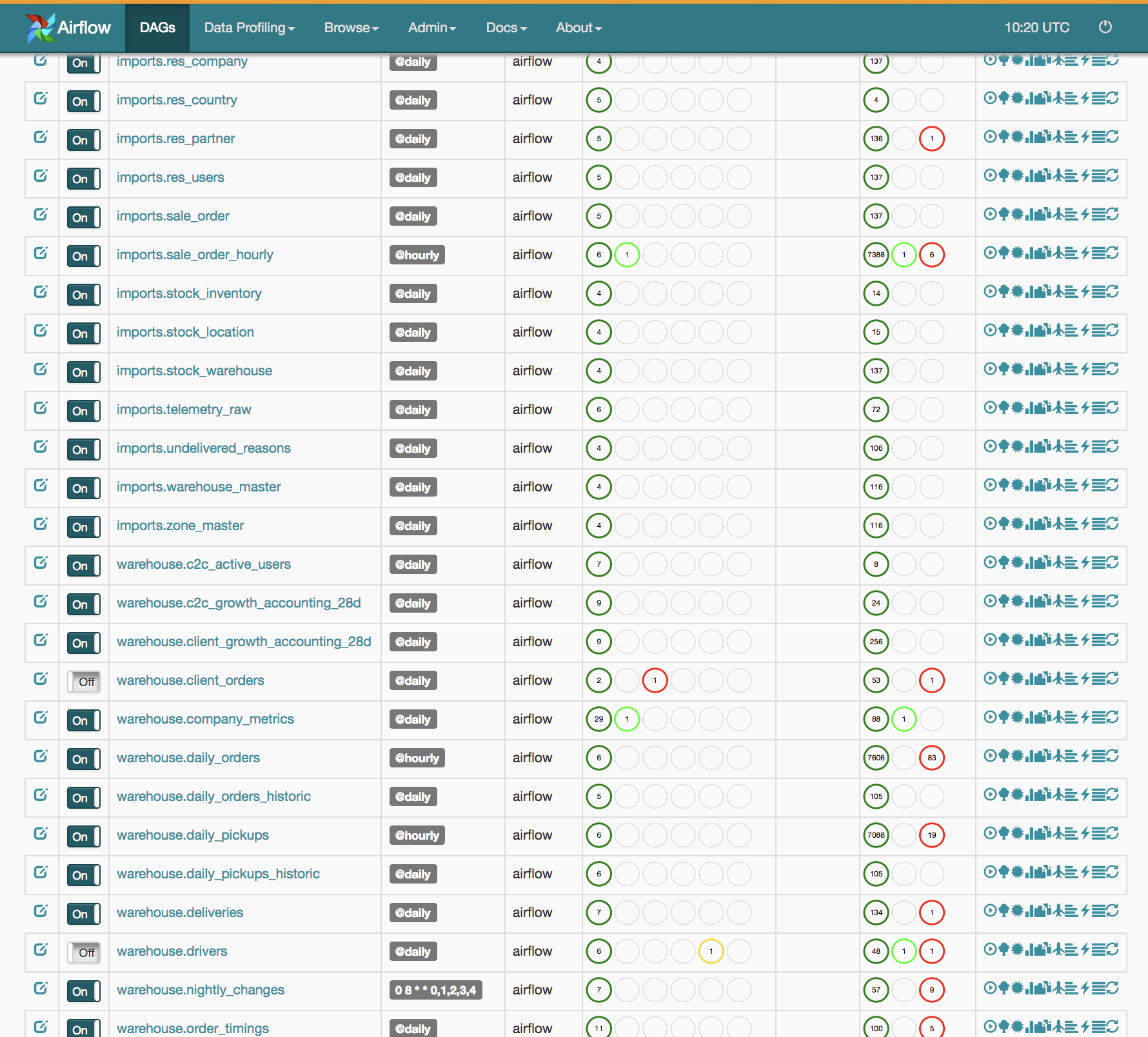
Similarly to Luigi, workflows are specified as a DAG of tasks in Python code. But there are many differences. Luigi knows that tasks operate on targets (datasets, files) and includes this abstraction; eg. it checks the existence of targets when deciding whether to run a task (if all output targets exists, there’s no need to run the task). This concept is missing from Airflow, it never checks for the existence of targets to decide whether to run a task. Like in Luigi, tasks depend on each other (and not on datasets). Unlike Luigi, Airflow supports the concept of calendar scheduling, ie. you can specify that a DAG should run every hour or every day, and the Airflow scheduler process will execute it. Unlike Luigi, Airflow supports shipping the task’s code around to different nodes using pickle, ie. Python binary serialization.
Airflow also has a webserver which shows dashboards and lets users edit metadata like connection strings to data sources. Since everything is stored in the database, the web server component of Airflow is an independent gunicorn process which reads and writes the database.
Execution
In Airflow, the unit of execution is a Task. DAG’s are made up of tasks, one .py file is a DAG. See tutorial. Although you can tell Airflow to execute just one task, the common thing to do is to load a DAG, or all DAGs in a subdirectory. Airflow loads the .py file and looks for instances of class DAG. DAGs are identified by the textual dag_id given to them in the .py file. This is important, because this is used to identify the DAG (and it’s hourly/daily instances) throughout Airflow; changing the dag_id will break dependencies in the state!
The DAG contains the first date when these tasks should (have been) run (called start_date), the recurrence interval if any (called schedule_interval), and whether the subsequent runs should depend on each other (called depends_on_past). Airflow will interleave slow running DAG instances, ie. it will start the next hour’s jobs even if the last hour hasn’t completed, as long as dependencies permit and overlap limits permit. An instance of a DAG, eg. one that is running for 2016-01-01 06:00:00 is called a DAGRun. A DAGRun is identified by the id of the DAG postfixed by the execution_date (not when it’s running, ie. not now()).
Tasks, like DAGs are also identified by a textual id. Internally, instances of tasks are instances of TaskInstance, identified by the task’s task_id plus the execution_date.
The tasks in a DAG may define dependencies on other tasks using set_upstream() and set_downstream(). Airflow will raise an exception when it finds cycles in the DAG.
A task is a parameterized operator. Airflow provides many types of operators, such as BashOperator for executing a bash script, HiveOperator for executing Hive queries, and so on. All these operators derive from BaseOperator. In line with Airflow being “an SQLAlchemy app”, BaseOperator is derived from SQLAlquemy's Base class, so objects can be pushed to the database; this pattern happens throughout Airflow. Operators don’t actually contain the database specific API calls (eg. for Hive or Mysql); this logic is contained in hooks, eg. class HiveCliHook. All hooks are derived from class BaseHook, a common interface for connecting and executing queries. So, whereas Luigi has one Target class (and subclasses), in Airflow this logic is distributed into operators and hooks.
There are 3 main type of operators (all three use the same hook classes to accomplish their job):
- Sensor: Waits for events to happen. This could be a file appearing in HDFS, the existence of a Hive partition, or waiting for an arbitrary MySQL query to return a row.
- Remote Execution: Triggers an operation in a remote system. This could be an HQL statement in Hive, a Pig script, a map reduce job, a stored procedure in Oracle or a Bash script to run.
- Data transfers: Move data from one system to another. Push data from Hive to MySQL, from a local file to HDFS, from Postgres to Oracle, or anything of that nature.
The most interesting are sensors. They allow tasks to depend on special “sensor tasks”, which are actually files or datasets. A sensor let’s you specify how often it should be checked (default 1 minute), and when it should time out (default 1 week). These are all derived from class BaseSensorOperator. There is a special sensor called ExternalTaskSensor, which lets a task depend on another task (specified by a dag_id and a task_id and execution_date) in another DAG, since this is not supported “by default”. ExternalTaskSensor actually just checks what the specified record looks like in the Airflow state database.
All operators have a trigger_rule argument which defines the rule by which the generated task get triggered. The default value for trigger_rule is all_success and can be defined as “trigger this task when all directly upstream tasks have succeeded. Others are: all_failed, all_done, one_failed, one_success.
Scheduling and executors
Recap: Airflow supports calendar scheduling (hour/daily tasks). Each such run is an instance of a DAG (internally, a DAGRun object), with tasks and their dependencies. As mentioned previously, DAGs can depend on their previous runs (depends_on_past), and additionally, specific task dependencies across DAGs is possible with the ExternalTaskSensor operator. The maximum number of DAG runs to allow per DAG can be limited with max_active_runs_per_dag in airflow.cfg.
When running Airflow, we have to specify what sort of executor to use in airflow.cfg: SequentialExecutor, LocalExecutor or CeleryExecutor; all three derive from BaseExecutor. The sequential executor runs locally in a single process/thread, and waits for each task to finish before starting the next one; it should only be used for testing/debugging. The LocalExecutor also runs tasks locally, but spawns a new process for each one using subprocess.popen() to run a new bash; the maximum number of processes can be configured with parallelism in airflow.cfg. Inside the bash, it runs an airflow, parameterized to just run the a given dag_id task_id execution_date combination using the airflow run command line parametrization. The python code belonging to the task is read back from the database (where it was stored by the scheduler using pickle). The CeleryExecutor works similarly, except the job is pushed inside a distributed celery queue.
When running Airflow, internally a number of jobs are created. A job is a long running something that handles running smaller units of work; all jobs derive from BaseJob. There is SchedulerJob, which manages a single DAG (creates DAG runs, task instances, manages priorities), BackfillJob for backfilling a specific DAG, and LocalTaskJob when running a specific dag_id task_id execution_date combination (as requested by the LocalExecutor or the CeleryExecutor).
When running the airflow scheduler, the SchedulerJob supports loading DAGs from a folder: in this case, new code added/changed is automatically detected and loaded. This is very convenient, because new code just has to be placed on the production server, and it’s automatically picked up by Airflow.
So in Airflow there is no need to start worker processes: workers are spawned as subprocesses by the LocalExecutor or remotely by celery. Also, more than one scheduler/executor/main process can run, sitting on the main database. When running tasks, Airflow creates a lock in the database to make sure tasks aren’t run twice by schedulers; other parallelism is enforced by unique database keys (eg. only one dag_id execution_date combination allowed to avoid schedulers creating multiple DAGRun copies). Note: I’m not sure what the point would be of running several schedulers, other than redundancy, and whether this truly works without hiccups; the TODO file includes this todo item: “Distributed scheduler”.
Airflow supports pools to limit parallelism of certain types of tasks (eg. limit number of bash jobs, limit number of Hive connections); this is similar to Luigi resources. Priorities are also supported: The default priority_weight is 1, and can be bumped to any number. When sorting the queue to evaluate which task should be executed next, Airflow uses the priority_weight, summed up with all of the priority_weight values from tasks downstream from this task.
Airflow supports heartbeats. Each job will update a heartbeat entry in the database. If a job hasn’t updated it’s heartbeat for a while, it’s assumed that it has failed and it’s state is set to SHUTDOWN in the database. This also allows for any job to be killed externally, regardless of who is running it or on which machine it is running. Note: I’m not sure how this works, because from my reading of the code, the actual termination of the process that didn’t send the heartbeat should be performed by the process itself; but if it stuck or blocked and didn’t send a heartbeat, then how will it notice it should shut itself down?
Other interesting features
SLAs: Service Level Agreements, or time by which a task or DAG should have succeeded, can be set at a task level as a timedelta. If one or many instances have not succeeded by that time, an alert email is sent detailing the list of tasks that missed their SLA. The event is also recorded in the database and made available in the web UI under Browse -> Missed SLAs where events can be analyzed and documented.
XCom: XComs let tasks exchange messages, allowing more nuanced forms of control and shared state. The name is an abbreviation of “cross-communication”. XComs are principally defined by a key, value, and timestamp, but also track attributes like the task/DAG that created the XCom and when it should become visible. Any object that can be pickled can be used as an XCom value, so users should make sure to use objects of appropriate size. XComs can be “pushed” (sent) or “pulled” (received). When a task pushes an XCom, it makes it generally available to other tasks. Tasks can push XComs at any time by calling the xcom_push() method. In addition, if a task returns a value (either from its Operator’s execute() method, or from a PythonOperator’s python_callable() function), then an XCom containing that value is automatically pushed. Tasks call xcom_pull() to retrieve XComs, optionally applying filters based on criteria like key, source task_ids, and source dag_id. By default, xcom_pull() filters for the keys that are automatically given to XComs when they are pushed by being returned from execute functions (as opposed to XComs that are pushed manually).
Variables: Variables are a generic way to store and retrieve arbitrary content or settings as a simple key value store within Airflow. Variables can be listed, created, updated and deleted from the UI (Admin -> Variables) or from code. While your pipeline code definition and most of your constants and variables should be defined in code and stored in source control, it can be useful to have some variables or configuration items accessible and modifiable through the UI.
Contrib stuff
Like Luigi, Airflow has an impressive library of stock operator classes:
- Bash
- Mysql
- Postgresql
- MSSQL
- Hive
- Presto
- HDFS
- S3
- HTTP sensor
- and many more... Redshift is currently not supported.
Source code and tests
The main codebase is ~21,000 LOC (python, js, html), plus about ~1,200 lines of unit test code. Other Python libraries used on the server side:
- SQLAlchemy
- Jinja for templating (why, if we’re using Python code to define jobs anyway?)
- Gunicorn and Flask for HTTP
- Dill for pickling
- Tox for testing and many more...
Conclusion
Airflow’s design decisions are very close to my heart: the fact that it’s an SQLAlchemy app make managing state, restarting the daemon, or running more in parallel very easy. It has lots of contrib stuff baked in, so it’s easy to get started. The dashboard is very nice, and also shows historic runs nicely color-coded. If I were to build a new ETL system, I would definitely consider using Airflow (over Luigi, since Airflow has many more features out of the box).
What I don’t like about Airflow:
- Apart from special sensor operators, doesn’t deal with files/datasets as inputs/outputs of tasks directly. This I find an odd design decision, as it leads to some complications:
- The state database stores the state of tasks, not the datasets; if the state database is lost, it’s hard to restore the historic state of the ETL, even if all the datasets are there. It’s better to separate datasets and tasks, and represent the historic state of ETL using the state of the datasets
- It’s harder to deal with tasks that appear to finish correctly, but don’t actually produce output, or good output. In the Airflow architecture this problem only shows up later, when a task downstream (hopefully) errors out. This can happen eg. if a bash script forgets to set -e.
- I think it’d be better if workers could be started independently, and picked up tasks scheduled by a central scheduler; instead Airflow starts workers centrally.
- Still a work in progress, not many tests, probably will run into bugs in production. Also see the end of this blog post, they restart the Airflow process pretty often because of some bug.
- Personally, I'm still not convinced that the ETL-job-as-code is the right way to go.