Predicting party affiliation of US politicians using fasttext
Marton Trencseni - Sun 20 June 2021 - Data
Introduction
Recently a colleague pointed me to the excellent fasttext text classification library from Facebook. The promise of fasttext is that we don't have to bother with regularizing the text, tokenizing, hand-engineering the tokens. We just feed the raw text and labels, and get a working classifier model within seconds.
![]()
There is a short 4 page paper describing the topline architecture of fasttext here. As of 2016, when the paper was written, fasttext was on-par with deep neural networks for text classification tasks. FastText: Under the Hood from Towards Data Science explains some of the internals of fasttext, I will not discuss it here.
The ipython notebook is up on Github.
Dataset
I wanted to use an interesting and relatable toy dataset, so I went with a dump of 1.2M tweets from U.S. politicians, such as Donald Trump and Adam Schiff. The dataset contains a total of 1,243,370 tweets from a total of 548 politicians.
I tried two toy exercises with this dataset:
- build a binary classification model to predict the political affiliation (Democrat or Republican) of the author (ignoring Independents and Libertarians)
- build a model to predict the author of a tweet (harder)

Enriching the dataset
To run the above exercises, I need to transform the tweets into a list of tuples like:
(screen_name, party, text)
Like:
(screen_name='RepAdamSchiff', party='Democrat', text='Admin review should be accompanied by thorough investigation by both House & Senate Intel Committees, perhaps meeting in joint session.')
screen_name and text is in the json files, but party is not. For that, I wrote a script to scrape each politician's Wikipedia page, which contains the party in a structured format in the page's infobox:
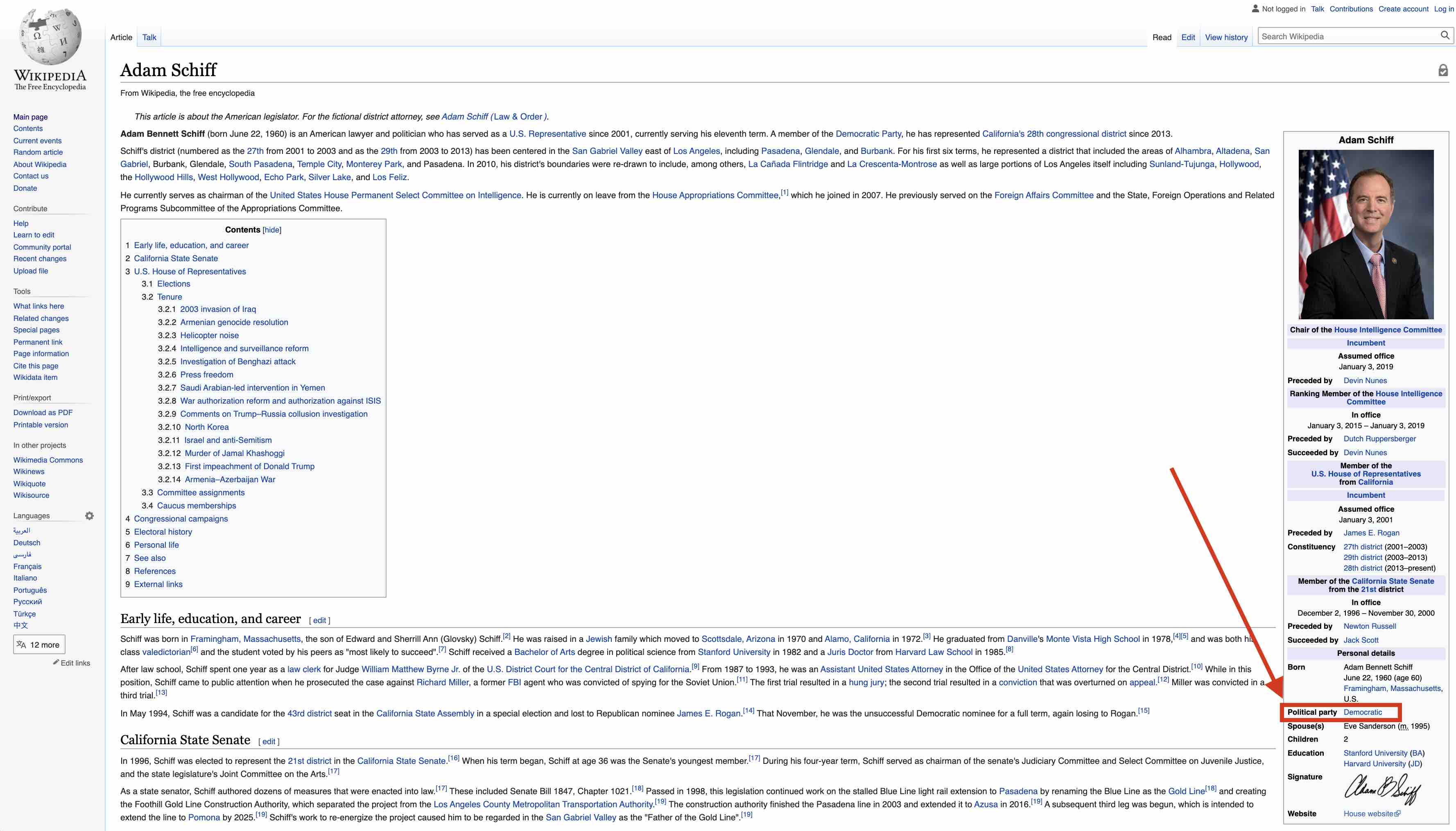
The function is called with the poitician's name attached to the Twitter account, which is also contained in the data dump:
def fetch_politician_info(name):
info = {}
info['name'] = name
info['wiki_page'] = ''
info['party'] = ''
try:
normalized_name = normalize_name(name)
search_url = 'https://en.wikipedia.org/w/api.php?action=query&list=search&format=json&srsearch=' + normalized_name + ' american politician'
wiki_page = requests.get(search_url).json()['query']['search'][0]['title']
info['wiki_page'] = 'https://en.wikipedia.org/wiki/' + wiki_page.replace(' ', '_')
wiki_info_url = 'https://en.wikipedia.org/w/api.php?action=query&prop=revisions&rvprop=content&rvsection=0&redirects=1&format=json&titles=' + wiki_page
result = requests.get(wiki_info_url).json()
pages = result['query']['pages']
for _, v in pages.items():
lines = v['revisions'][0]['*'].split('\n')
for line in lines:
if line.startswith('| party') or line.startswith('|party'):
for party in parties:
if party.lower() in line.lower():
info['party'] = party
return info
except:
pass
finally:
return info
For example:
fetch_politician_info('Adam Schiff')
> {
> 'name': 'Adam Schiff',
> 'wiki_page': 'https://en.wikipedia.org/wiki/Adam_Schiff',
> 'party': 'Democratic'
> }
This method works for 537 out of 548 of the politicians (~98%). The remaining few I looked up manually. The final counts for the political affiliations:
Democratic: 242
Republican: 301
Independent: 4
Libertarian: 1
Limiting information content of tweets
Examining the tweets I found that some signals may make classification too simple. For example, authors often @mention each other. I didn't check this, but I assume Dems are more likely to mention other Dems, and so on. Also, tweets often contains (shorted) URLs, which may also give away the author's identity or affiliation. So I tried the classification tasks both with the full tweet text, and with the @mentions and URLs removed.
Fasttext input format
Fasttext does not take dataframes or Python lists as input. The input needs to be a file, 1 line per data point. The target label is just part of the text, with a special prefix to designate it. The default prefix is __label__.
For predicting the author, I emit lines like:
Admin review should be accompanied by thorough investigation by both House & Senate Intel Committees,
perhaps meeting in joint session __label__RepAdamSchiff
For predicting the party, I emit lines like:
Admin review should be accompanied by thorough investigation by both House & Senate Intel Committees,
perhaps meeting in joint session __label__Democratic
Train-test split
I sort the tweets by create time, and use the first 1,000,000 for training and the chronological tail, 243,370 tweets for test. This way there is no data leakage from train to test (other than at the boundary, which I ignore for this toy exercise), eg. a test tweet that is just a retweet of a training tweet.
Using fasttext
This is where fasttext shines. Ones I build the training file per the above format, it's as simple as:
model = fasttext.train_supervised(file_path)
Training the model on 1M data points takes about 5 seconds on an 8-core Intel Macbook Pro.
Once the model is trained, predicting on a piece of text is also simple:
# sample tweet from Trump
txt = """
Mike Pence didn’t have the courage to do what should have been done
to protect our Country and our Constitution, giving States a chance to
certify a corrected set of facts, not the fraudulent or inaccurate ones
which they were asked to previously certify. USA demands the truth!
""".replace('\n', ' ')
model.predict(txt)
(('__label__Republican',), array([0.79000771]))
Accuracy of the fasttext models
First, how well does fasttext do predicting the political party of the author? I only kept Dems and Reps, and re-balanced both the training and test set, so for this binary-classification exercise, the baseline accuracy is 50%. The balanced dataset has 881,460 training tweets (down from 1,000,000) and 195,804 test tweets (down from 243,370). With the original tweet texts:
Train accuracy: 92.9%
Test accuracy: 74.6%
After removing @atmentions and URLs:
Train accuracy: 85.2%
Test accuracy: 71.8%
Second, let's see how fasttext does predicting the author of the tweets? This is a C=548 classification problem, so the baseline random predictor would achieve 1/548=0.1% accuracy. Compared to this, fasttext achieves, on the original tweet texts:
Train accuracy: 51.2%
Test accuracy: 22.9%
After removing @atmentions and URLs:
Train accuracy: 41.1%
Test accuracy: 18.4%
Conclusion
Fasttext is very convenient to use, and saves a lot of time that would be spent manually regularizing, normalizing and tokenizing the text and then manually building feature vectors. In terms of runtime, it's very fast, both for training and prediction. Although I have no other baseline available for the above toy example, the accuracy fasttext achieves out of the box is promising. Predicting the full author is a hard problem, but fasttext does ~200x better than the random baseline out-of-the-box, which is impressive.
I'm a bit surprised fasttext only achieves ~75% accuracy on the binary Dem-or-Rep classification problem, I expected this to be a tractable problem, where ~90%+ accuracy is achievable. By default, fasttext does not build multi-word n-words, so I tried running it with wordNgrams=2 and 3, but it didn't improve accuracy. I may re-visit this problem in the future with a hand-built classifier to get a comparison baseline.