100 articles
Marton Trencseni - Mon 18 October 2021 - meta
Introduction
The previous article, Cross entropy, joint entropy, conditional entropy and relative entropy was the 💯th post on Bytepawn! I took a few hours and reviewed my writing so far.

First article
I wrote the first article, Cargo Cult Data, in 2015 January because I saw that many companies are not getting the most out of their data and data teams due to organizational and cultural discipline issues. At that time, the issues I saw were flaky logs, no standardized metrics, or constant and pointless arguments around data (eg. correlation vs causation, trustwortyness). The topic of cargo culting is still relevant, but today I would write a different article. Since then I've worked at a lot more companies, and what I called "cargo culting" is the way things are at most companies — the only exception I've seen is Facebook (the company). Since then Data Science and AI have exploded and moved the topic of conversation away from traditional analytics topics like logging and A/B testing. DS/ML/AI have their own set of problems which are not best described by the "cargo cult" analogy. The final reason I would write a different article today, being almost 7 years wiser, is that today I believe it's not constructive to be confrontative on such issues. It's better to educate people, leading by showing, which is why later I wrote so many posts on data and A/B testing related topics here.

Airflow
When I left my job at Prezi I took a month off before joining Facebook (the company), and I spent some time reviewing open source ETL tools. At Prezi we spent a lot of time building hand-rolled ETL tools, one in bash, a second one in Haskell and a third one in golang. By the end of my tenure I realized this is crazy, there must be (or should be) a good enough open source solution. I reviewed Airflow, Luigi and Pinball and finally wrote a 3-way comparison piece. To this day, this gets a lot of daily long-tail hits — people are stil curious about what ETL tool to use. My takeaway then was that Airflow is the way forward. Since then Airflow has become the de-facto open source ETL tool. At Facebook I didn't use Airflow, we had something called Dataswarm, but I learned that Airflow is actually based on Dataswarm (written by an ex-Facebook engineer who left the company). So after leaving Facebook, I've set up Airflow and made it the standard ETL tool at all subsequent jobs, also teaching team members how to use it (building an Airflow job is always part of onboarding). Over the years I've also written a few more articles on how we use Airflow in production. The biggest "trick" — which I hope every team figures out — is that we always write helper functions that internally construct DAGs, so my less technical Data Scientist teammates can just ignore the technicalities and use a template for building DAGs. We currently use Airflow for both SQL transform jobs as well as ML model building (for which it is less ideal), and I plan to continue to use Airflow in the future.
Fetchr
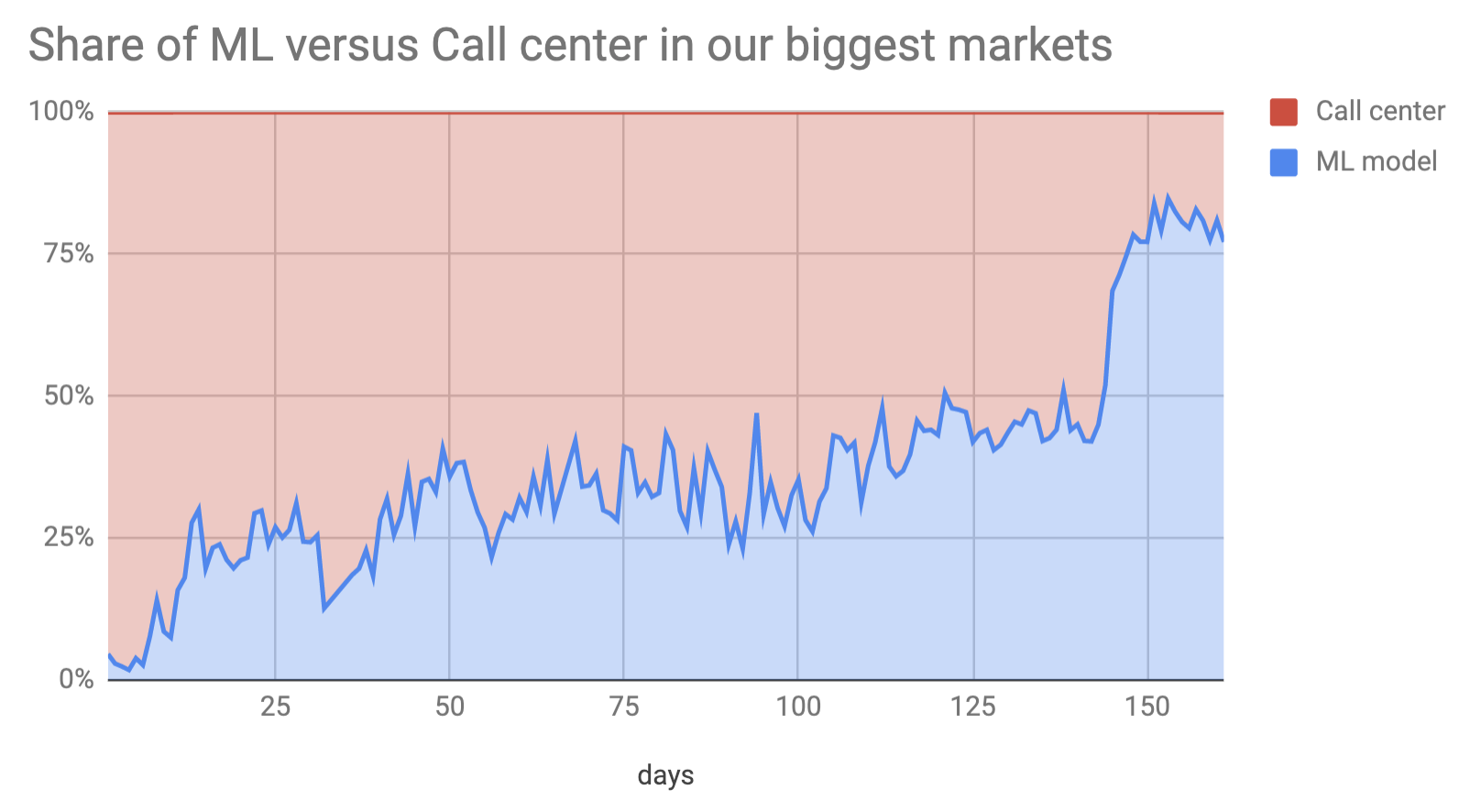
My first job in Dubai, after I left Facebook and London, was at a last mile delivery startup called Fetchr. One of the upsides about working at Fetchr was that, unlike at Facebook, I could write about work related topics freely, nobody cared. I wrote about 10 articles about interesting Data Science work we did at Fetchr. I'm especially fond of the article Automating a Call Center with Machine Learning, this service is probably the most impactful piece of software I've ever written: it ended up saving about $3-5m/yr for Fetchr, which was about 3-5% of expenses at that time. It's been 2 years since I left, unfortunately Fethcr is not doing too well.
Pytorch
The following are all true for the Deep (and Reinforcement) Learning revolution: (i) the productization opportunities are genuinely exciting (ii) everybody's talking about it (iii) it's very interesting technically (iv) yet, very few companies are doing it in production. Big tech does use DL in production, but in my experience almost all other companies don't, because 80-90% of tabular business problems can be solved by SQL, scripting and dashboarding. For the remaining 10-20% there is some benefit in using Scikit-Learn models (tree-based models, gradient boosting, etc) or building FBProphet forecasts (or similar libraries like XGBoost or LGBM). Whenever I actually use a neural network at work, it's usually when I'm building a classifier, and I'm playing around with Scikit-Learn's LogisticRegression, DecisionTreeClassifier, RandomForestClassifier, GradientBoostingClassifier, etc. models and I also try and see how MLPClassifier performs with 2-3 hidden layers. Usually I decide against it, since performance is either not superior or within 1-2% of the second best, but training is slow and convergence is not always deterministic.
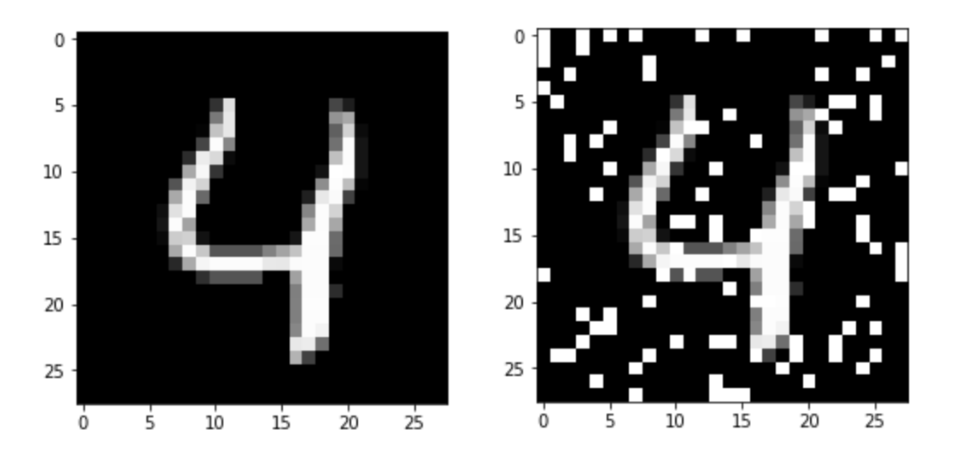
I still had to learn Deep Learning! It's so interesting, exciting, and you first have to know what it is before you can make a good call whether to (not) use it for a given problem. So I used this blog to drive my learning, writing an article on each mini-project I built. I cast my vote for Pytorch (vs Tensorflow), because of it's native integration with Python which makes learning, experimentation and debugging easy (vs the Tensorflow runtime model). Some of the articles took a lot of time (also runtime), up to 20-40 hours sometimes. All in all I wrote 18 posts tagged pytorch. The approach worked, I know the basics (and a bit more) about Deep (and Reinforcement) Learning. My favorites articles are the ones where I go beyond getting something to work, such as seeing how many pixels I have to change on MNIST digits to break a deep neural network classifier or the one where I play around with the information storage capacity of autoencoders.
Craftmanship
I love thinking and writing about craftmanship. Craftmanship are the little things such as indenting SQL code properly, formatting numbers and charts so they're readable, or writing readable regular expressions. Articles from this theme:
- Beat the averages
- Literate and composable regular expressions
- Metrics Atlas
- Calibration curves for delivery prediction with Scikit-Learn
- How I write SQL code
- SQL best practices for Data Scientists and Analysts
- Validation checks for A/B tests
- Effective Data Visualization Part 1: Categorical data
- Effective Data Visualization Part 2: Formatting numbers
- Effective Data Visualization Part 3: Line charts and stacked area charts
A/B testing
The most frequent topic I wrote about is A/B testing, there are 20 articles tagged A/B testing. In my experience writing clean SQL code and the concepts of A/B testing are the two most important skills in Data Science and Analytics — but very few people are clear on them. 4 out of 5 people I interview cannot explain to me what a p-value is. This is why I wrote articles such as Building intuition for p-values and statistical significance. I had a lot of fun with running Monte Carlo simulations of A/B testing on random graphs (A/B testing on social networks and A/B testing and networks effects.
A/B testing was also my greatest blunder on Bytepawn. In this article I incorrectly claimed that it's a fallacy to look at historic (before the A/B test) data. This post made it to the Hacker News front page (most don't), and people called me out on this incorrect claim and pointed me to something called CUPED. This was painful, because in all my A/B testing articles I run Monte Carlo simulations to check my thinking, and here I got lazy and did not. This was a good reminder for me that although A/B testing seems like an easy subject, it's easy to mislead yourself, even for somebody who spends a lot of time thinking about it. It's always better to check your thinking with simple Monte Carlo simulations. But, this way I learned about CUPED, and wrote 5 articles on it — with Monte Carlo simulations, of course!

Pelican
Pelican is the static site generator I use for Bytepawn. I wrote an article about it, what's changed since then is now I host it myself (with nginx and Let's Encrypt) to avoid the ~10 second delays when changing content with Github Pages. The combination of writing articles in Markdown, not worrying too much about formatting and Pelican has worked well in the past 5 years, I don't plan to change it. I don't want to switch to something like Medium, because this way I have and feel more ownership for the blog.
Conclusion
Writing the first 100 articles has been great fun, I hope and plan to write another 100! I write this blog for fun, it's not monetized, I don't regularly push the links to broadcast-social-media like Hackers News, only to my local-social-media (my Facebook and Linkedin). It used to get around 50-100 readers a day, this year it went up to 100-150 per day, probably because I write regularly: one of my yearly goals is to write 40 blog posts in 2021 (I'm on track). Much more is not doable next to work and family, but I'll try to push myself to write 50 in 2022, and it'd be nice to have ~250 readers a day. A big question to myself is whether I should start writing articles about Physics — time will tell!
Onward to the next 💯!