A/B testing and networks effects
Marton Trencseni - Sat 21 March 2020 • Tagged with ab-testing
I use Monte Carlo simulations to explore how A/B testing on Watts–Strogatz random graphs depends on the degree distribution of the social network.
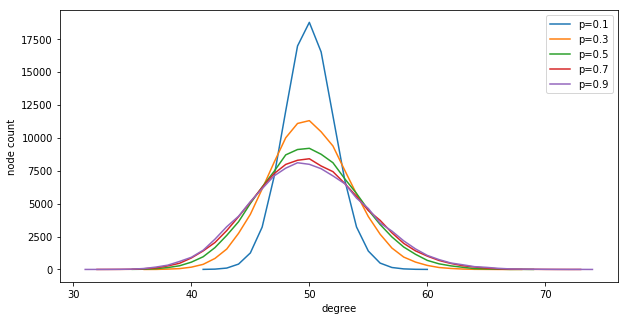
Marton Trencseni - Sat 21 March 2020 • Tagged with ab-testing
I use Monte Carlo simulations to explore how A/B testing on Watts–Strogatz random graphs depends on the degree distribution of the social network.
Marton Trencseni - Mon 09 March 2020 • Tagged with ab-testing
I use Monte Carlo simulations to show that experimentation on social networks is a beatiful statistical problem with unexpected nuances due to network effects.
Marton Trencseni - Thu 05 March 2020 • Tagged with ab-testing
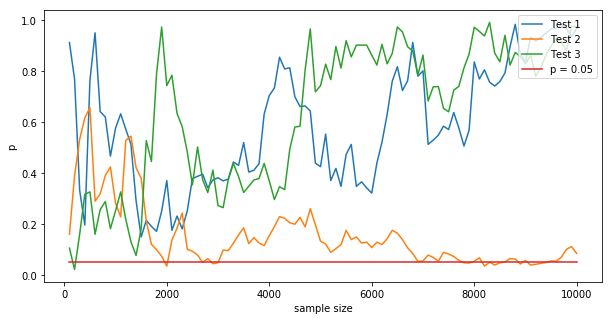
Increased false positive rate due to early stopping is beautiful nuance of statistical testing. It is equivalent to running at an overall higher alpha. Data scientists need to be aware of this phenomenon so they can control it and keep their organizations honest about their experimental results.
Marton Trencseni - Tue 03 March 2020 • Tagged with ab-testing
Fisher’s exact test directly computes the same p value as the Chi-squared test, so it does not rely on the Central Limit Theorem to hold.
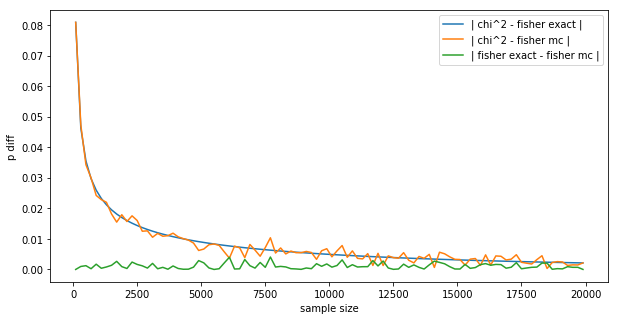
Marton Trencseni - Fri 28 February 2020 • Tagged with ab-testing
In an ealier post, I wrote about A/B testing conversion data with the Z-test. The Chi-squared test is a more general test for conversion data, because it can work with multiple conversion events and multiple funnels being tested (A/B/C/D/..).
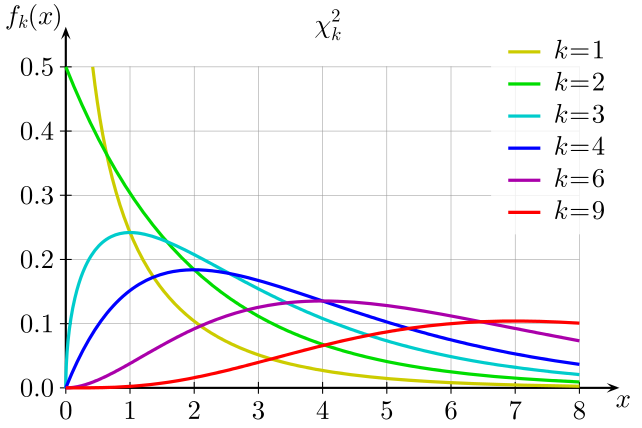
Marton Trencseni - Sun 23 February 2020 • Tagged with ab-testing
The t-test is better than the z-test for timespent A/B tests, because it explicitly models the uncertainty of the variance due to sampling. Using Monte-Carlo simulations I show that around N=100, the t-test becomes the z-test.
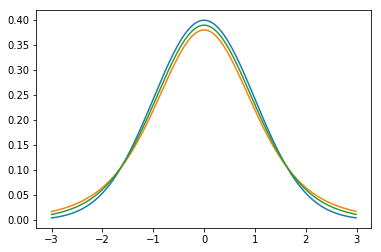
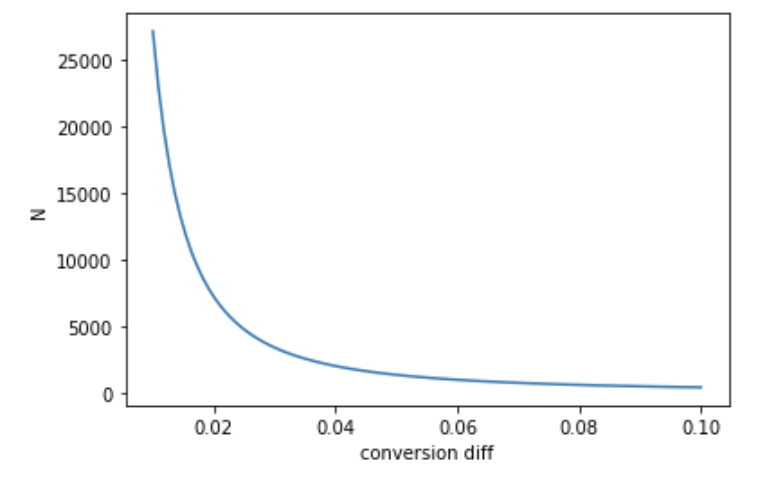
Marton Trencseni - Sat 15 February 2020 • Tagged with ab-testing
I discuss the Z-test for A/B testing and show how to compute parameters such as sample size from first principles. I use Monte Carlo simulations to validate significance level and statistical power, and visualize parameter scaling behaviour.
Marton Trencseni - Sat 01 February 2020 • Tagged with data, airflow, python
Sometimes I get to put on my Data Engineering hat for a few days. I enjoy this because I like to move up and down the Data Science stack and I try to keep myself sharp technically. Recently I was able to spend a few days optimizing our Airflow ETL for speed.
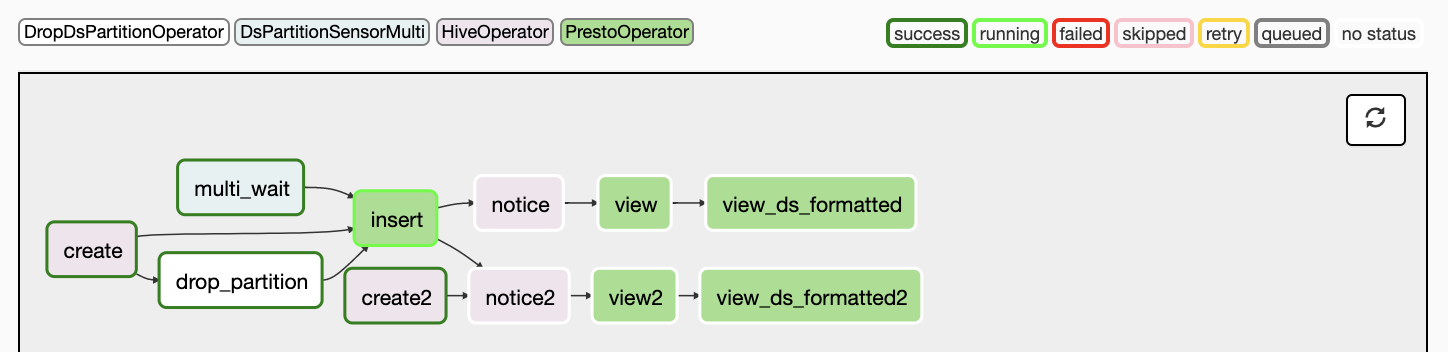
Marton Trencseni - Sun 26 January 2020 • Tagged with data, programming, sql
My list of SQL best practices for Data Scientists and Analysts, or, how I personally write SQL code. I picked this up at Facebook, and later improved it at Fetchr.

Marton Trencseni - Fri 24 January 2020 • Tagged with data, programming, sql
This is a simple post about SQL code formatting. Most of this comes from my time as a Data Engineer at Facebook.

Marton Trencseni - Thu 29 August 2019 • Tagged with data, fetchr
The idea is simple: write a document which helps new and existing people—both managers and individual contributors—get an objective, metrics-based picture of the business. This is helpful when new people join, when people start working in new segments of the business, and to understand other parts of the company.
Marton Trencseni - Wed 09 January 2019 • Tagged with data, openai, waymo, deepmind, tesla, reinforce
2018 was a hot year for Data Science and AI. Here we picked out 5 highlights, which in our opinion shaped the field in the past year.
Marton Trencseni - Wed 26 September 2018 • Tagged with data, data-science, metrics, fetchr
Sometimes, the seven gods of data science, Pascal, Gauss, Bayes, Poisson, Markov, Shannon and Fisher, all wake up in a good mood, and things just work out. Recently we had such an occurence at Fetchr, when the Operational Excellence team posed the following question: if we could pick our Saudi warehouse locations, where would be put them? What is the ideal number of warehouses, and, what does ideal even mean? Also, what should our “delivery radius” be?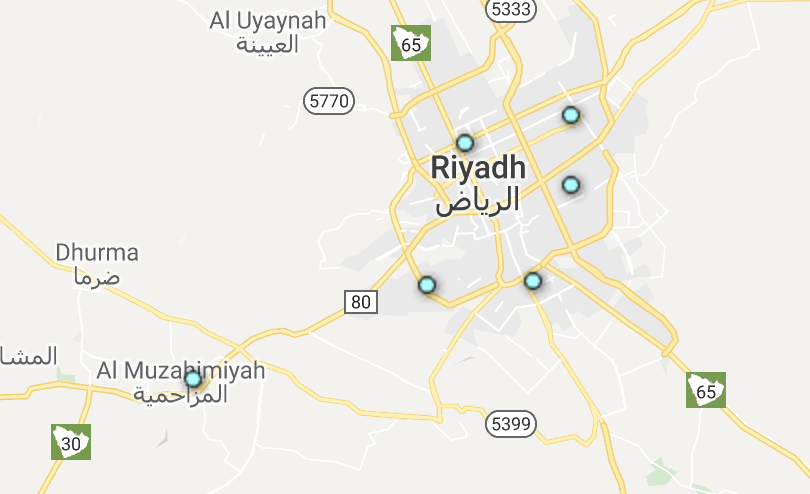
Marton Trencseni - Sun 16 September 2018 • Tagged with data, data-science, metrics, growth-accounting, fetchr
Previously I wrote two articles about data infra and data engineering at Fetchr. This time I want to move up the stack and talk about a simple piece of metrics engineering that proved to be very impactful: Growth Accounting and Backtraced Growth Accounting.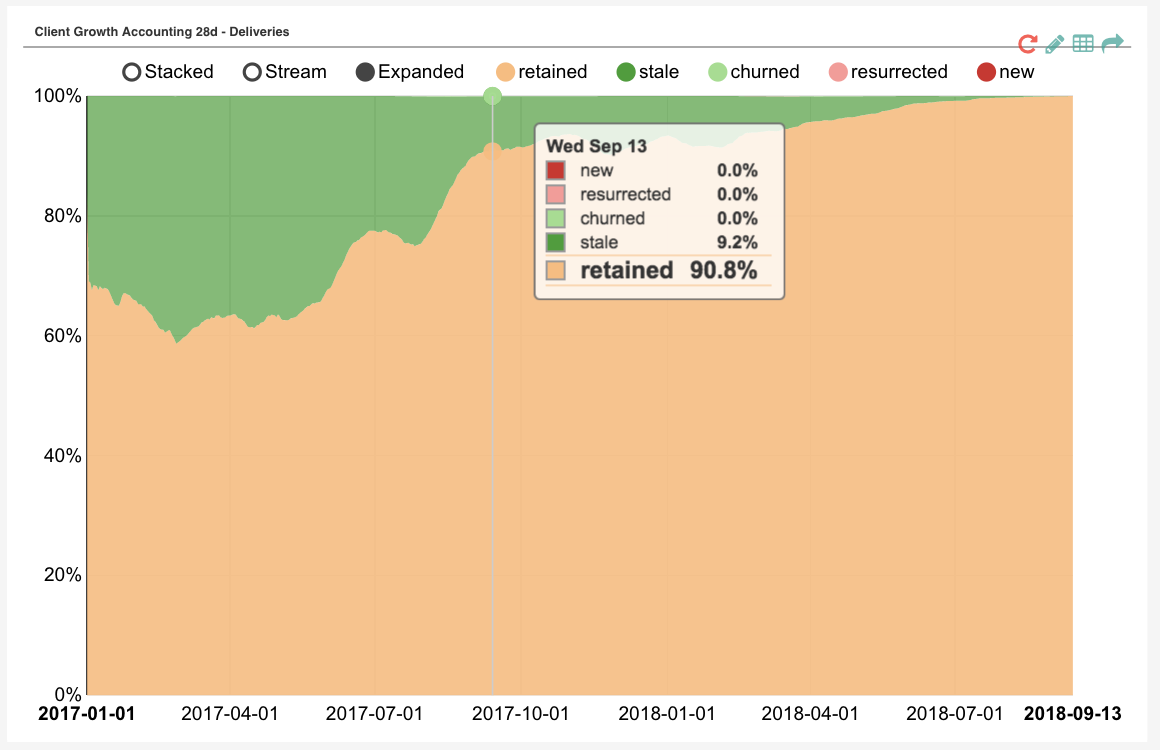
Marton Trencseni - Tue 14 August 2018 • Tagged with data, etl, workflow, airflow, fetchr, model, ml
A description of our Analytics+ML cluster running on AWS, using Presto, Airflow and Superset.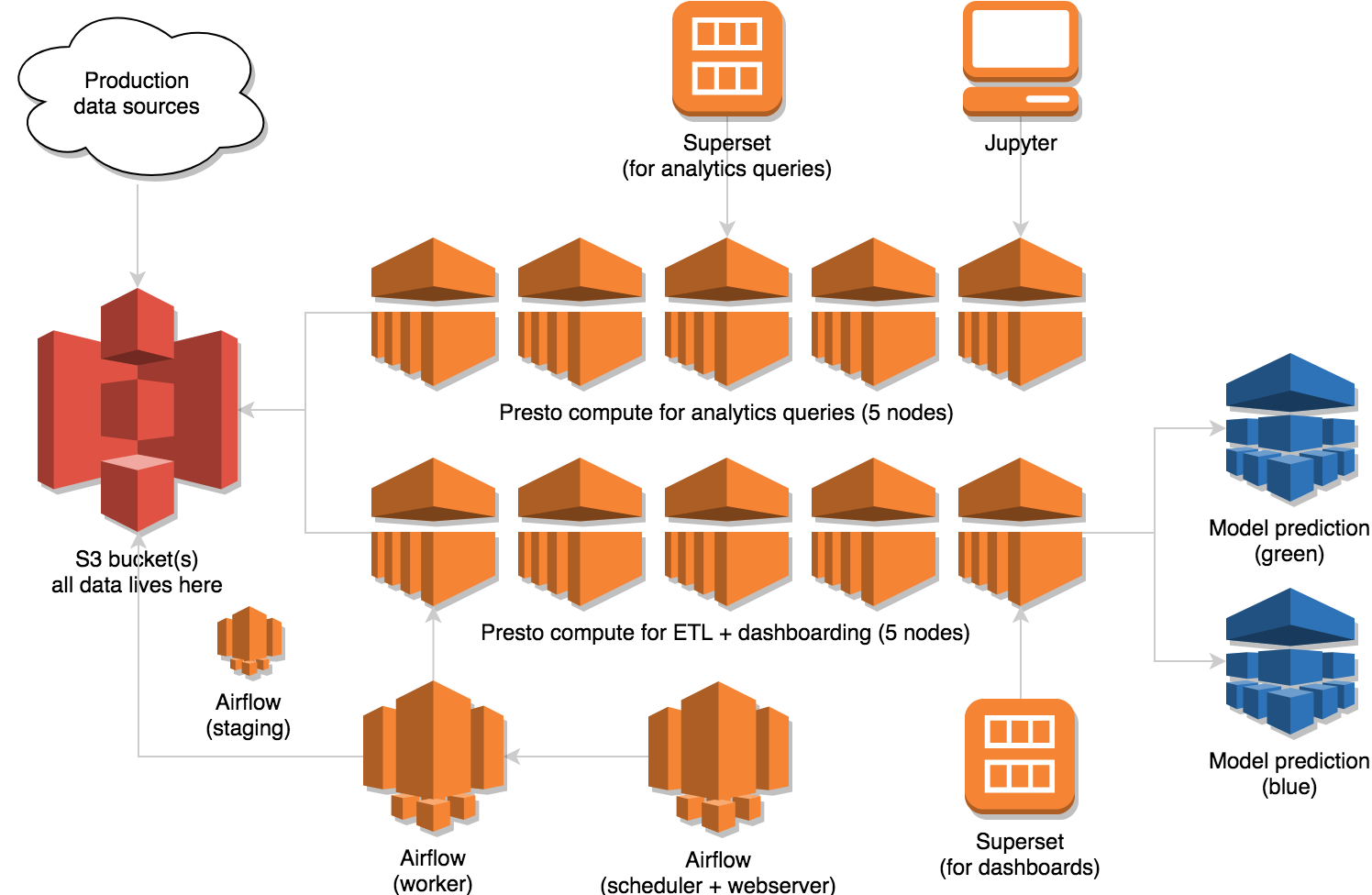
Marton Trencseni - Sat 07 July 2018 • Tagged with statistics, data
When working with averages, we have to be careful. There are pitfalls lurking to pollute our statistics and results reported.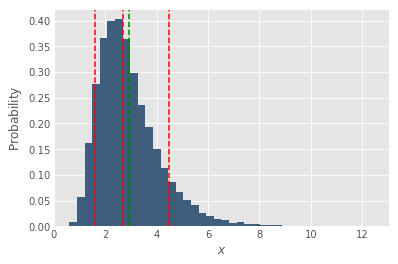
Marton Trencseni - Wed 14 March 2018 • Tagged with data, etl, workflow, airflow, fetchr
We used Hive/Presto on AWS together with Airflow to rapidly build out the Data Science Infrastructure at Fetchr in less than 6 months.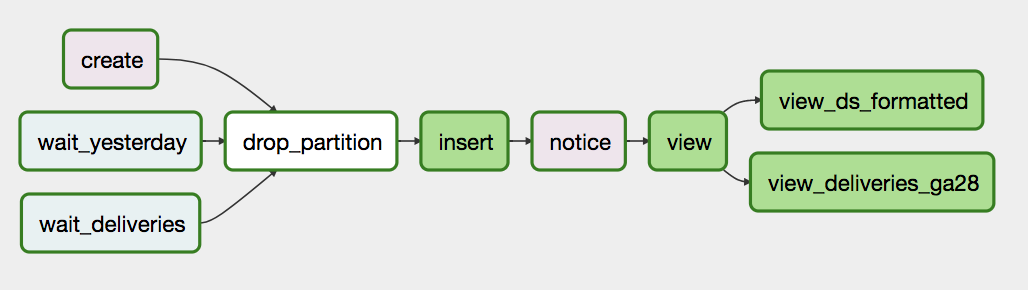
Marton Trencseni - Sat 06 February 2016 • Tagged with data, etl, workflow, luigi, airflow, pinball
A spreadsheet comparing the three opensource workflow tools for ETL.
Marton Trencseni - Sat 06 February 2016 • Tagged with data, etl, workflow, pinball
Pinball is an ETL tool written by Pinterest. Like Airflow, it supports defining tasks and dependencies as Python code, executing and scheduling them, and distributing tasks across worker nodes. It supports calendar scheduling (hourly/daily jobs, also visualized on the web dashboard). Unfortunately, I found Pinball has very little documentation, very few recent commits in the Github repo and few meaningful answers to Github issues by maintainers, while it's architecture is complicated and undocumented.
Continue readingMarton Trencseni - Wed 06 January 2016 • Tagged with data, etl, workflow, airflow
Airflow is a workflow scheduler written by Airbnb. It supports defining tasks and dependencies as Python code, executing and scheduling them, and distributing tasks across worker nodes. It supports calendar scheduling (hourly/daily jobs, also visualized on the web dashboard), so it can be used as a starting point for traditional ETL. It has a nice web dashboard for seeing current and past task state, querying the history and making changes to metadata such as connection strings.